It’s been about two weeks since I started on pancreatic enzyme replacement therapy (PERT) and it’s been really interesting to experience the difference it is making for me.
For context (and you can read more here), I have moderate exocrine pancreatic insufficiency (EPI or PEI), but I have very obvious symptoms following anything I eat for a few hours, as well as next-day bathroom habits. My clinician didn’t think trying PERT would be a problem even though my elastase levels were only borderline low, and it didn’t hurt. It definitely helped in multiple ways.
Here’s what the experience has been like starting on PERT, what I like about it, what I found challenging, what it’s like to scientifically titrate your dosing of PERT, and a handful of random other thoughts.
Here is what I like about Pancreatic Enzyme Replacement Therapy (PERT)
With undiagnosed EPI, for the last almost two years, I would eat food with dread. And not a lot of food (averaging 2 meals a day), because I had to severely limit the kinds of things I was eating to try to reduce my symptoms (with mixed success). With my first few doses of PERT, I ate relatively small, careful and low-FODMAP meals so I could better assess whether PERT was working.
And wow, was it working.
With the first few small (and low-FODMAP, to reduce variables that I was testing) meals, I had an immediate improvement. I didn’t realize until I took PERT how sick I felt every time I ate anything, even when I didn’t have obvious post-meal symptoms of gas, stabbing abdominal pain, or next-day bathroom habits. With PERT, I felt…nothing? Which is apparently how I used to feel after I would eat. There was no sick feeling, no bloating within an hour, and no discomfort for hours. There was no gas after I ate or overnight. In the morning, I didn’t have steatorrhea.
I got braver and experimented with a few bigger meals. In some cases, I still felt not-sick after I ate, but did develop some gas. However, it was significantly reduced.
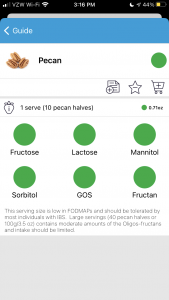
From tracking the cumulative fat and protein levels in everything I ate, I was able to see that things less than 50 grams of fat and protein (combined) worked exceptionally well with the level of PERT I had started on. PERT has different dosing options, and I had started on a relatively moderate dose. I saw that some of my 70-ish gram meals were fine, but the ones in the 90s definitely needed more PERT.
Even when I could tell I needed more PERT, though, it wasn’t a complete failure. Even for meals with 90+ grams of fat+protein, I had a reduction in feeling sick, way less gas, and improved bathroom habits, even if they weren’t as ideal as what happened when I ate <50g of fat and protein meals.
As I discussed in my previous post, I had felt like a boiling frog where I didn’t really feel good every day, but there was usually nothing obviously wrong (no broken bone, no stabbing pain every day). So it was hard to know what was wrong. Now, taking PERT, I can see a clear difference on the days when the dosing is well-titrated to what I’m eating (no symptoms after I eat, plus I feel a lot better!) compared to when the dosing isn’t optimal (reduced symptoms but still there, sometimes will still feel sick or abdominal discomfort).
I also now have back the lab results of the bloodwork I asked my gastroenterologist to run on fat-soluble vitamins (A, D, E) and iron, to make sure I didn’t have any deficiencies that need addressing. Thankfully, I didn’t – which is probably influenced by the fact that I am absorbing some of what I eat without PERT, but is also likely due to the fact that I take two multivitamins daily plus additional vitamin D supplements. I can imagine that I would have much lower levels without the supplementation, so I’m glad I had built the habit in the last two years of making sure I was taking my vitamins. (Which I wasn’t doing before two years ago consistently, and intuitively was worried about getting the right nutrients given the changes I was making to what I was eating, so that was a good habit to have built up!)
As a pleasant result of taking PERT, I’m also seeing improvements in symptoms that I did not think were correlated with EPI.
For example, in October I developed severely dry eyes, which I’ve never had before. I’ve been using lubricating eye drops several times a day and gel drops at night ever since. After about a week of PERT, I realized that I was waking up in the morning and my first thought wasn’t about putting drops in my eyes because they weren’t painfully dry. And then on days following when my PERT dosing wasn’t optimal (as evidenced by post-meal gas or abdominal discomfort, etc), my eyes are more dry than they are on the other days.
Another thing I’ve noticed is the skin on my face improving. In the last year, I started having more acne breakouts and changes to my skin tone. This, like the eye dryness, has started to noticeably improve in the last week or so (with no other changes to routine or the weather: it’s still winter here!).
What I find challenging about Pancreatic Enzyme Replacement Therapy (PERT)
There’s not a lot of guidance to patients regarding PERT titration (changing dosing levels as needed). My GI doc wrote a script for one size and said we could size up if it wasn’t working. That was it.
Thankfully, I have 19 years of experience with titrating insulin dosing for everything I’m eating, and I have an inclination to use spreadsheets to track things, so I began to take PERT and write down the relevant details of what I was eating (date, timing, what it was, how much fat and protein it had, what PERT dose I took), the result (any post-meal symptoms including timing) and whether it caused steatorrhea or other bathroom-related changes. From this, I was able to very quickly group meals into “wow that worked awesome”, “hmm, this reduced symptoms but it wasn’t perfect”, and “wow that needed more PERT”. For me, those roughly ended up being <50 grams combined of fat and protein (“wow that worked awesome”), around 70 grams (“hmm, this reduced symptoms but it wasn’t perfect on every front”), and more than 90 grams (“wow that needed more PERT”).
Interestingly, a lot of the medical literature I read about PERT indicates that most people are not taking enough. Given my analysis of my own data, that’s currently true. (Personally I’m currently trying to collect more data in each category before I discuss dosing with my clinician, to figure out what dosing or prescription I might need).
I’m only two weeks in, so I can’t yet give solid advice to anyone else taking PERT, but I imagine in the future I would likely feel more confident saying the following to someone else starting on PERT:
- If you can, write down the date, timing, what you eat, and the nutrients (e.g. fat, protein, and carb) of what you’re eating, and track what symptoms you have when following a meal. Also make sure to note how many and what dose of PERT you took.
- See if you can group the data between which meals turned out well, which could be improved, and what didn’t work. That may help you discuss with your doctor what level of enzyme you need for what type of meal.
Anecdotally in the EPI communities, people discuss taking 3-4 of the largest dose PERT for meals, vs 1-2 for their snacks. It seems to be very, very individual about what people need. Some people (like me with moderate EPI) have symptoms, others can have severe insufficiency (severe EPI) but have fewer symptoms. As a result, we may need more or less PERT, depending on how our bodies are generating symptoms.
One frustration I have about GI-related conditions, whether that’s those that result in people using the low FODMAP diet or EPI resulting in the need for PERT – and even in the diabetes community where insulin is needed – is that there’s very much a perception of individual blame in the day-to-day operations. If you have symptoms, you probably did something wrong. You ate a high FODMAP thing, or you ‘stacked’ FODMAPs…or for EPI, you didn’t take enough PERT or you ate the wrong thing. In diabetes, you didn’t take enough insulin, or you did it at the wrong time, or you forgot, or you ate too much, or you ate the wrong thing…. There is SO much blame and shame going around, and it’s frustrating to see (and experience).
Having tracked my data for two weeks now, I can see very clear cause and effect in the data: when I feel great, my PERT dosing has been well-matched to what I was eating. When I have some symptoms, the PERT dosing was not-optimal, and sometimes as a result I have a lot of symptoms and don’t feel well. It’s a very clear cause and effect relationship between having sufficient enzymes or not having enough enzymes. I am working to not feel guilty, e.g. I did something ‘wrong’ by choosing the wrong sized meal to go with the PERT dosing, and instead frame it as data that I’m collecting to inform the future prescription I need of PERT.
(My point here is that I don’t like the blame/shame that goes around, and yet, I still feel it, too. I’m trying to remove myself from those patterns of thinking, because it’s not at all helpful.)
It’s helpful instead for me to think “Wow, that was not enough PERT this time! Next time I should take 2 of this dose, or supplement my single PERT with standalone lipase” rather than feel shame or guilt because I ate a “big” meal. This is in part why I’m trying to stay away from thinking and using words like “big” or “small” meal, because the size is so arbitrary, depending on whether you’re looking at volume of food on a plate, thinking about calories, carbohydrates (to take insulin for it), or the fat and protein amounts (to dose PERT for it).
Also, everyone with EPI is likely VERY different from one another, and so my cutoffs of 70 or 90g of fat+protein may be numerically more or less than what someone else needs. (Those who take PERT will also notice I am very careful to not specify what PERT dose my one pill is, because everyone’s needs are different, and I don’t want anyone to accidentally anchor on my dose numbers, because what I need may not be what everyone else needs.)
And I can imagine some folks without EPI reading this with their own perceptions of fat and protein levels thinking judgmental thoughts about the numerical amounts of what I’m eating at different times.
Having to track fat and protein makes me grumpy, for a few reasons. In part, because it’s “one more thing” to track (in addition to general carbohydrate estimates to be able to dose insulin or inform my automated insulin delivery system about what I’m eating). In part, because I set up a spreadsheet to learn from what I’m doing, so I need to count it, input it into my spreadsheet, and then analyze the data later. I know I won’t always need to do this, and eventually I’ll learn intuitively what dosing I need for different types of meals.
But, I now have to remember to get out my PERT, take it “with the first bite” (which I interpret as swallow the PERT and then immediately try to put a bite of food in my mouth so I match the timing of the food with the PERT), then write down the timing of when I took my PERT and input the fat and protein and details of the meal into my spreadsheet…and then remember to also enter carbohydrates into my automated insulin delivery system (which I don’t have to do, but I get better outcomes with a meal announcement so I want to do so. When I’m not working on PERT titration, it doesn’t feel like a burden.).
—
Although I am grumbling about the titration learning curve and process of figuring out my dosing and what I am eating, I know it’s like any learning curve: I will figure it out soon, and the routine of taking PERT will become as easy as remembering to enter carbs or take insulin for what I’m eating.
And as a short-term benefit and reward of learning to dose PERT for what I’m eating, I feel so much better. Immediately, after every meal, as well as the next day, and I also feel better overall while improving other ‘symptoms’ that I didn’t realize were correlated with my EPI. Hooray!

PS – make sure to check out my other posts about EPI at DIYPS.org/EPI, including the one about PERT Pilot, the first iOS app for Exocrine Pancreatic Insufficiency that I built! It’s an iOS app that allows you to record as many meals as you want, the PERT dosing and outcomes, to help you visualize and review more of your PERT dosing data!
—
You can also contribute to a research study and help us learn more about EPI/PEI – take this anonymous survey to share your experiences with EPI-related symptoms!
—








Recent Comments