 If you have been prescribed pancreatic enzyme replacement therapy (PERT), aka enzymes for exocrine pancreatic insufficiency (EPI or PEI), you may be wondering how long it will take before you start to feel better or it starts to work. This is a common question, and the answer depends on several factors, including the dosage, meal composition, and how well your body uses the enzymes. Some improvements can be seen within a single meal, while other benefits take longer to manifest. It also depends on whether you have EPI, or if you have EPI in concert with other types of gastrointestinal conditions, because some of your symptoms may be coming from other conditions.
If you have been prescribed pancreatic enzyme replacement therapy (PERT), aka enzymes for exocrine pancreatic insufficiency (EPI or PEI), you may be wondering how long it will take before you start to feel better or it starts to work. This is a common question, and the answer depends on several factors, including the dosage, meal composition, and how well your body uses the enzymes. Some improvements can be seen within a single meal, while other benefits take longer to manifest. It also depends on whether you have EPI, or if you have EPI in concert with other types of gastrointestinal conditions, because some of your symptoms may be coming from other conditions.
Immediate Effects of PERT
PERT should start working with your very first meal, if your dose is in the ballpark of being ideal for you and your food intake. The enzymes help break down fats, proteins, and carbohydrates so your body can absorb nutrients more effectively. If you are taking somewhere in the ballpark of the right dose, you may notice immediate improvements in digestion, such as:
- Less bloating or cramping after eating
- Reduced gas
- A decrease in diarrhea or greasy, foul-smelling stools
These improvements should occur on a per-meal basis. If you take PERT with one meal but not another, you may notice a stark difference in symptoms after each of those meals. This is a good indicator that the enzymes are working when you do take them.
Why Some People Don’t See Immediate Improvement With PERT
While PERT can provide relief after a meal or noticeable effects within a day or so, many people do not take a sufficient dose initially. Under-dosing is common, which means you may still experience symptoms as you fine-tune your enzyme intake.
Here are some reasons why you might not see immediate results:
- Not taking enough enzymes: Many people are prescribed a starting dose well below the standard guidelines, and this may not be enough for their specific needs. This is because your body is unique, and what you eat varies from what other people eat. The combination of these two factors means that your dose is not going to be the same as someone else’s, regardless of which “category” of EPI you fall into or even with an identical fecal elastase test result. If you still experience symptoms, you may need to increase your dose of enzymes.
- Miscalculating enzyme dosing: If you eat a small salad with a few bites of chicken, this is likely a lower fat and lower protein meal, when you compare it to a large hamburger with bacon and cheese and a side of french fries. These meals likely need different doses of enzymes. The dose you start with may work for some of your existing meals, but don’t be surprised if you have symptoms with meals with more protein or more fat than your lower quantity meals. Some people can use the same, fixed dose for all their meals…but that usually means their meals don’t vary a lot. Other people like me can have a wide range of meal quantities, so we adjust our dosing for every meal. (It gets easier over time!)
- Enzyme timing may be wrong: PERT needs to be taken with the first few bites of a meal, and sometimes additional enzymes are needed if the meal is prolonged. It’s ok if you get halfway through a meal and haven’t taken your enzymes – start taking them then. But don’t take them well before you eat or well after. The point is to get them into your system at the same time that you are eating (or drinking any drink with fat/protein). If you have a 5 course meal at a restaurant that lasts 2 hours, you will need to take more enzymes even if your usual dose would normally cover the total quantity of what you consumed. The fact that it’s so spread out matters. Rule of thumb most people use is 20-30 minutes, so if you’re eating longer than that, you likely need another pill (or more than one more).
- Other gastrointestinal conditions: Some people have additional digestive issues such as SIBO or other conditions like pancreatitis that have their own symptoms, and it can be challenging to tell what are EPI-specific symptoms due to enzyme dosing or timing issues as opposed to symptoms of these other conditions.
Here are some example scenarios where you might not see the improvements right away:
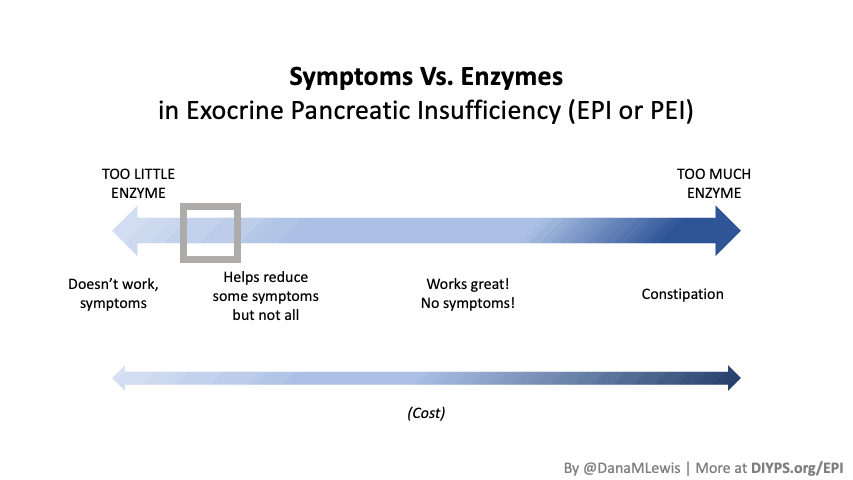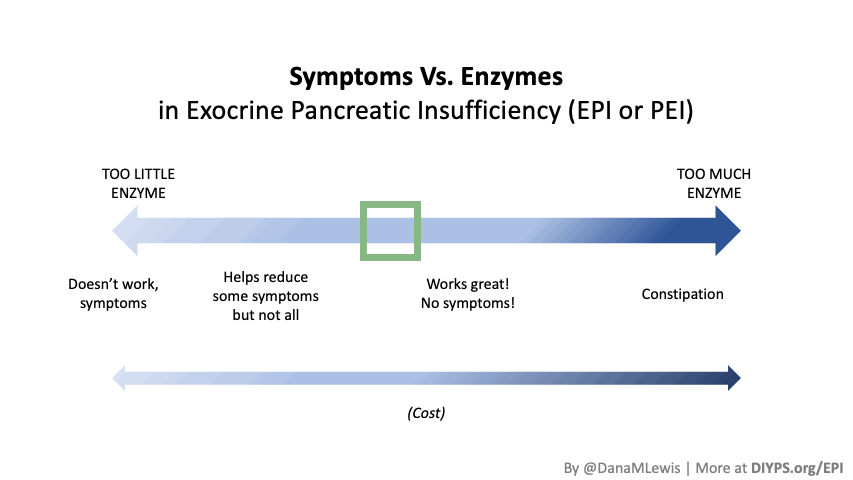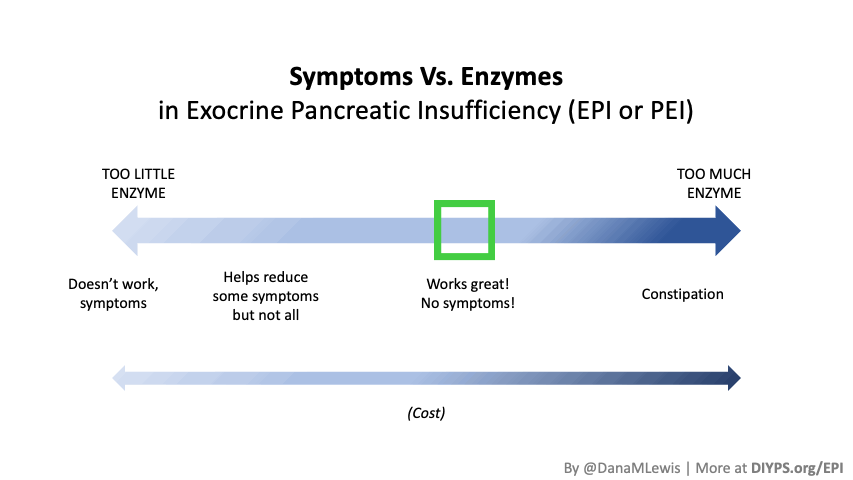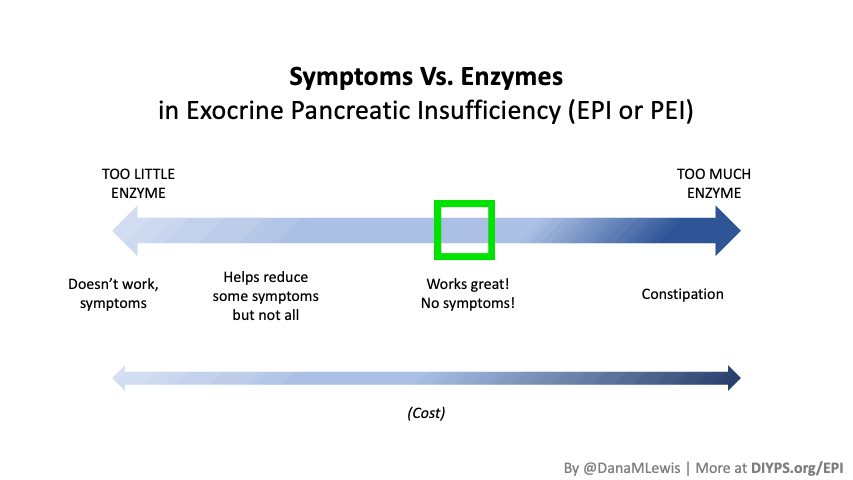
- If you eat a hamburger with fries as your first meal, but your prescription is for two pills of 10,000 lipase of PERT. This is unlikely to be enough for the meal, as the standard dose for regular meals is 40-50,000 units; many people need more than that; and this type of meal is higher in fat and protein than a standard meal. Thus, symptoms.
- If you take your PERT 30 minutes before you eat, even if the dose matches your food perfectly, the timing is off and the enzymes won’t be where they need to be to help digest your food. Thus, symptoms.
Short-Term vs. Long-Term Improvements
Short-Term (Days to Weeks)
Once you find the right PERT dosage, the most noticeable and immediate improvements should occur within your first several meals and across a few days, including:
- Reduction in diarrhea or loose stools
- Less bloating and discomfort after eating
- Improved stool consistency
- Decreased urgency to use the bathroom
If you are still experiencing symptoms after a few days of consistent PERT use, consider adjusting your dose, especially in the context of looking at what quantity is in your meal. (You’ll find some other tips here walking you through how to look at what’s in your food and how to track it, including tools like PERT Pilot for tracking it on your phone over time.)
Long-Term (Weeks to Months)
While digestion-related symptoms can improve within days, some longer-term health effects take weeks or months to resolve or notice improvements. These include:
- Nutritional deficiencies: If you have been malabsorbing fats and nutrients for a long time, it may take months of improved digestion to correct deficiencies in fat-soluble vitamins (A, D, E, K), iron, or B12.
- Weight stabilization: Weight gain or stabilization may occur over weeks to months. (Not everyone gains weight, but if you’re looking for weight gain to occur after you improve digestion with enzymes, it will take some time).
- Improved energy levels: Once your body starts absorbing nutrients more efficiently, you may notice a gradual increase in energy.
Do some people see improvement on these and other symptoms sooner? Yes! However, it’s different for everyone, so don’t expect every single symptom to magically get better after your first few days on PERT.
How to Know If PERT Is Working for You
The key to determining if PERT is effective lies in tracking your symptoms and adjusting accordingly. Signs that your PERT is working include:
- Well-formed stools without oiliness or a greasy appearance
- Normal bowel movement frequency (not too frequent or urgent)
- Reduction in gas, bloating, and stomach discomfort
- Gradual improvements in weight and energy levels over time, if those were bothersome to you before
Note a key factor that does NOT tell you if PERT is working for you, which is that changes in fecal elastase score do not tell you anything about whether your enzymes are working for you. Elastase is not affected directly by your enzymes, meaning the elastase test measures human elastase (and enzymes are not human elastase, so they’re not measured by the elastase test). Elastase can naturally fluctuate a bit over time; test precision is not perfect; and for a lot of reasons it’s common to see different numbers in elastase. Read this blog post for a lot more detail, but a change from 23 to 84, or from 154 to 137, or from 58 to 101 are not meaningful changes and do not change the diagnosis of EPI. The categorization of EPI as ‘moderate’ or ‘severe’ does not matter for either diagnosis overall (EPI is EPI) and does not matter for whether or not enzymes are effective because elastase can’t answer that question.
When to Adjust or Reassess Enzyme Dosing
If you do not see some improvements within a few meals or a few days, it may indicate that your dose is too low or not properly timed or you are eating different size meals and need to pay attention to your dose size relative to what you are eating. Work with your healthcare provider to fine-tune your dosage (note that they may not be aware of the guidelines for starting doses or aware that dose ranges vary person to person), and consider tracking your meals and symptoms to identify patterns. Once you’ve ruled that out, say by tracking your meals and increasing your doses and eating consistently sized meals, you may want to investigate other conditions contributing to symptoms.
For most people, PERT should start showing effects within a single meal if the dose is in the ballpark of being correct, even if it’s not fully covering your meal. However, because under-dosing is common, it may take days or weeks of adjustments to see consistent improvement or to improve or eliminate all symptoms.
Immediate symptoms like bloating, diarrhea, and gas should improve quickly (days to weeks), while long-term nutritional recovery (if you had any nutritional deficiencies) may take longer (weeks to months).
Other posts you may find helpful:
- Why you should know – and consider – your baseline numbers (and how to find them) before considering advice for “more” or “less” of anything with EPI (PEI)
- Understanding what the fecal elastase test can tell us
- How to dose pancreatic enzyme replacement therapy (PERT) based on what you are eating
- How to talk to your doctor about adjusting your enzyme dose
 TL;DR: Instead of arbitrarily lowering or increasing fat or fiber in the diet, measure and estimate what you are consuming first. If you have EPI,
TL;DR: Instead of arbitrarily lowering or increasing fat or fiber in the diet, measure and estimate what you are consuming first. If you have EPI,  It occurred to me that maybe I could tweak it somehow and make the bullets of the list represent food items. I wasn’t sure how, so I asked the LLM if it was possible. Because I’ve done my other ‘design’ work in PowerPoint, I went there and quickly dropped some shapes and lines to simulate the icon, then tested exporting – yes, you can export as SVG! I spent a few more minutes tweaking versions of it and exporting it. It turns out, yes, you can export as SVG, but then the way I designed it wasn’t really suited for SVG use. When I had dropped the SVG into XCode, it didn’t show up. I asked the LLM again and it suggested trying PNG format. I exported the icon from powerpoint as PNG, dropped it into XCode, and it worked!
It occurred to me that maybe I could tweak it somehow and make the bullets of the list represent food items. I wasn’t sure how, so I asked the LLM if it was possible. Because I’ve done my other ‘design’ work in PowerPoint, I went there and quickly dropped some shapes and lines to simulate the icon, then tested exporting – yes, you can export as SVG! I spent a few more minutes tweaking versions of it and exporting it. It turns out, yes, you can export as SVG, but then the way I designed it wasn’t really suited for SVG use. When I had dropped the SVG into XCode, it didn’t show up. I asked the LLM again and it suggested trying PNG format. I exported the icon from powerpoint as PNG, dropped it into XCode, and it worked! If you can shift your mindset from fear and avoidance to curiosity and experimentation, you might discover new skills, solve problems you once thought were impossible, and open up entirely new opportunities.
If you can shift your mindset from fear and avoidance to curiosity and experimentation, you might discover new skills, solve problems you once thought were impossible, and open up entirely new opportunities.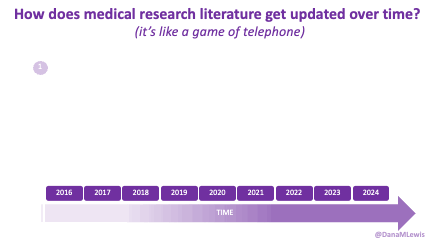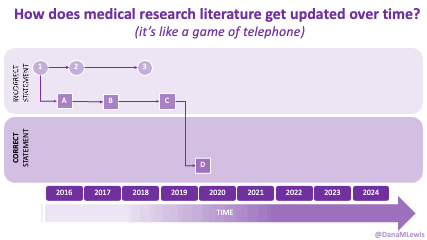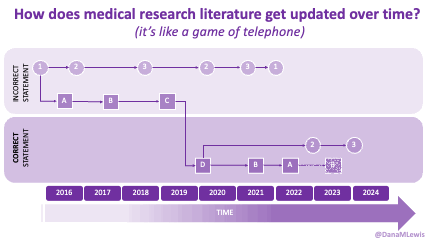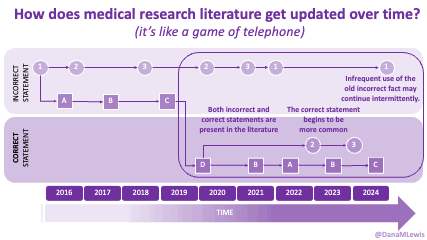
Recent Comments