One of the challenges related to diagnosing exocrine pancreatic insufficiency (known as EPI or PEI) is that there is no perfect test.
With diabetes, we can see in several different ways what glucose is doing: via fasting glucose levels, HbA1c (an average of 3 months glucose), and/or continuous glucose monitoring. We can also test for c-peptide to see if insulin production is ongoing.
Yet for EPI, the tests for assessing whether and how much the pancreas is producing digestive enzymes are much less direct, more invasive, or both.
Some of the tests include a breath test; an invasive secretin pancreatic function test; a 72-hour fecal fat collection test, or a single sample fecal elastase test.
- A breath test is an indirect test, which assesses the end-product of digestion rather than digestion itself, and other conditions (like SIBO) can influence the results of this test. It’s also not widely available or widely used.
- The secretin pancreatic function test is an invasive test involving inserting a tube into the small intestine after giving secretin, which is a hormone that stimulates the pancreas. The tube collects digestive juices produced by the pancreas, which are tested. It’s invasive, costly, and therefore not ideal.
- For reliability, the 72-hour fecal fat collection test might be ideal, because it’s checking the amount of fat in the stool. It requires stopping enzymes, if someone is taking them already, and consuming a high fat diet. But that includes collecting stool samples for 3 days – ugh. (The “ugh” is my personal opinion, clearly).
- The fecal elastase test, in contrast, does not require stopping enzymes. It measures human elastase, whereas digestive enzymes are typically pig-based, so you don’t have to stop enzymes when doing this test. It’s also a single stool sample (so you’re not collecting poop for 3 days in a row). The sensitivity and specificity are different based on the diagnostic threshold, which I’ll talk about below, and the accuracy can be influenced by the sample. Diarrhea, meaning watery poop, can make this test even less reliable. But that’s why it’s good that you can take enzymes while doing this test. Someone with diarrhea and suspected EPI could go on enzymes, reduce their diarrhea so they could have a formed (non-watery) sample for the elastase test, and get a better answer from the fecal elastase test.
The fecal elastase test is often commonly used for initial screening or diagnosis of EPI. But over the last two years, I’ve observed a series of problems with how it is being used clinically, based on reading hundreds of research and clinical practice articles and reading thousands of posts of people with EPI describing how their doctor is ordering/reviewing/evaluating this test.
Frequent problems include:
- Doctors refuse to test elastase, because they don’t believe the test indicates EPI due to the sensitivity/specificity results for mild/moderate EPI.
- Doctors test elastase, but won’t diagnose EPI when test results are <200 (especially if 100-200).
- Doctors test elastase, but won’t diagnose EPI even when test results are <100!
- Doctors test elastase, diagnose EPI, but then do not prescribe enzymes because of the level of elastase (even when <200).
- Doctors test elastase, diagnose EPI, but prescribe a too-low level of enzymes based on the level of elastase, even though there is no evidence indicating elastase should be used to determine dosing of enzymes.
Some of the problems seem to result from the fact that the elastase test has different sensitivity and specificity at different threshold levels of elastase.
When we talk about “levels” of elastase or “levels” or “types” of EPI (PEI), that usually means the following thresholds / ranges:
- Elastase <= 200 ug/g indicates EPI
- Elastase 100-200 ug/g indicates “mild” or “mild/moderate” or “moderate” EPI
- Elastase <100 ug/g often is referred to as “severe” EPI
You should know that:
- People with severe EPI (elastase <100) could have no symptoms
- People with mild/moderate EPI (elastase 100-200) could have a very high level of symptoms and be malnourished
- People with any level of elastase indicating EPI (elastase <=200) can have EPI even if they don’t have malnourishment (usually meaning blood vitamin levels like A, D, E, or K are below range).
So let’s talk about sensitivity and specificity at these different levels of elastase.
First, let’s grab some sensitivity and specificity numbers for EPI.
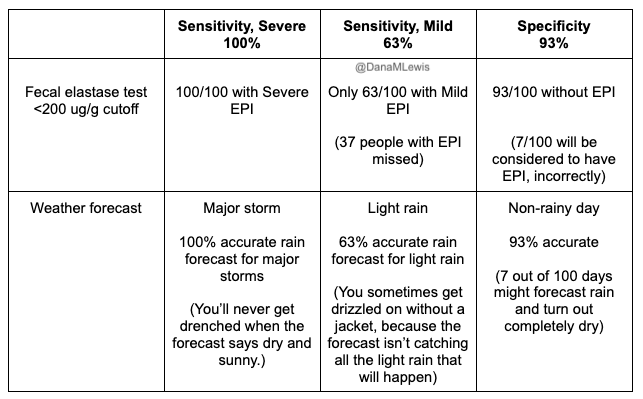
- One paper that is widely cited, albeit old, is of sensitivity and specificity of fecal elastase for EPI in people with chronic pancreatitis. You’ll see me talk in other posts about how chronic pancreatitis and cystic fibrosis-related research is over-represented in EPI research, and it may or may not reflect the overarching population of people with EPI.But since it’s widely used, I’ll use it in the below examples, especially because this may be what is driving clinician misunderstanding about this test.With a cut off of <200 ug/g, they found that the sensitivity in detecting moderate/severe EPI is 100%, and 63% sensitivity for detecting mild EPI. At that <200 ug/g threshold, the specificity is 93% (which doesn’t distinguish between severities). With a cut off of <100 ug/g, the sensitivity for detecting mild EPI drops to 50%, but the specificity increases to 98%.This means that:
- 63% of people with mild EPI would be correctly diagnosed using an elastase threshold of 200 ug/g (vs. only 50% at 100 ug/g).
- 100% of people with moderate/severe EPI would be correctly diagnosed using an elastase threshold of 200 ug/g (compared to only 93% or 96% for moderate/severe at 100 ug/g).
- Only 7% of people testing <200 ug/g would be incorrectly diagnosed with EPI, and only 2% of people testing <100 ug/g.
- For comparison, a systematic review evaluated a bunch of studies (428 people from 14 studies) and found an average sensitivity of 77% (95% CI of 58-89%) and average specificity of 88% (95% CI of 78-93%).This sensitivity is a little higher than the above number, which I’ll discuss at the end for some context.
So what does sensitivity and specificity mean and why do we care?
At an abstract level, I personally find it hard to remember what sensitivity and specificity mean.
- Sensitivity means: how often does it correctly identify the thing we want to identify?
This means a true positive. (Think about x-ray screening at airport security: how often do they find a weapon that is there?)
- Specificity means: how often does it avoid mistakenly identifying the thing we want to identify? In other words, how often is a positive a true positive rather than a false positive?
(Think about x-ray screening at airport security: how often does it correctly identify that there are no weapons in the bag? Or how often do they accidentally think that your jam-packed bag of granola and snacks might be a weapon?)
Here is how we apply this to fecal elastase testing for EPI.
For those with moderate/severe EPI, the test is 100% sensitive at correctly detecting those cases if you use an elastase cut off of <200 ug/g. For those with mild EPI, the test drops to only being 63% sensitive at correctly detecting all of those cases. And 93% of the time, the test correctly excludes EPI when it doesn’t exist (at a <200 ug/g cut off, vs. 98% of the time at a <100 ug/g cut off). Conversely, 7% (which we get from subtracting 93% from 100%) of people with elastase <200 ug/g might not have EPI, and 2% (98% subtracted from 100%) of people with elastase <100 ug/g might not have EPI.
Here’s another way of thinking about it, using a weather forecast analogy. Think about how easy it is to predict rain when a major storm is coming. That’s like trying to detect severe EPI, it’s a lot easier and forecasters are pretty good about spotting major storms.
But in contrast, what about correctly predicting light rain? In Seattle, that feels close to impossible – it rains a lot, very lightly. It’s hard to predict, so we often carry a light rain jacket just in case!
And for mild EPI, that’s what the sensitivity of 63% means: less than two thirds of the time can it correctly spot mild EPI by looking for <200 ug/g levels, and only half the time by looking for <100 ug/g. The signal isn’t as strong so it’s easier to miss.
The specificity of 93% means that the forecast is pretty good at identifying not-rainy-days, even with a cut off of elastase >200 ug/g. But, occasionally (around 7/100 times), it’s wrong.
Why might clinicians be incorrectly using the value of these numbers for the fecal elastase test?
I hypothesize that in many cases, for the elastase levels now considered to indicate mild/moderate EPI (elastase 100-200 ug/g), clinicians might be accidentally swapping the sensitivity (63%) and specificity (93%) numbers in their mind.
What these numbers tell us is that 63% of the time, we’ll catch mild EPI through elastase testing. This means 37/100 people with actual mild EPI might be missed!
In contrast, the specificity of 93% tells us about accidental false positives, and that 7/100 people without EPI might accidentally get flagged as having possible EPI.
Yet, the clinical practice in the real-world seems to swap these numbers, acting as if the accuracy goes the other way, suspecting that elastase 100-200 doesn’t indicate EPI (e.g. thinking 37/100 false positives, which is incorrect, the false positive rate is 7/100).
There’s plenty of peer-reviewed and published evidence that people with elastase 100-200 have a clear symptom burden. There’s even a more recent paper suggesting that those with symptoms and elastase of 200-500 benefit from enzymes!
Personally, as a person with EPI, I am frustrated when I see/hear cases of people whose clinicians refuse testing, or don’t prescribe PERT when elastase is <=200 ug/g, because they don’t believe elastase 100-200 ug/g is an accurate indicator of EPI. This data shows that’s incorrect. Regardless of which paper you use and which numbers you cite for sensitivity and specificity, they all end up with way more common rates of false negatives (missing people with EPI) than false positives.
And, remember that many people with FE 200-500 benefit from enzymes, too. At a cutoff of 200 ug/g, the number of people we are likely to miss (sensitivity) at the mild/moderate level is much higher than the number of false positives who don’t actually have EPI. That puts the risk/benefit calculation – to me – such that it warrants using this test, putting people on enzymes, and evaluating symptom resolution over time following PERT dosing guidelines. If people’s symptom burden does not improve, titrating PERT and re-testing elastase makes sense (and that is what the clinical guidelines say to do), but the cost of missing ~37 people out of 100 with EPI is too high!
Let’s also talk about elastase re-testing and what to make of changed numbers.
I often also observe people with EPI who have their elastase re-tested multiple times. Here are some examples and what they might mean.
- A) Someone who tests initially with a fecal elastase of 14, later retests as 16, then 42 ug/g.
- B) Someone who tests initially at 200 and later 168.
- C) Someone who tests initially at 72 and later 142.
- D) Someone who tests initially as 112 and later 537.
Remember the key to interpreting elastase is that <=200 ug/g is generally accepted as indicating EPI. Also it’s key to remember that the pancreas is still producing some enzymes, thus elastase production will vary slightly. But in scenarios A, B, and C – those changes are not meaningful. In scenario A, someone still has clear indicators of severe (elastase <100) EPI. Slight fluctuations don’t change that. Same for scenario B, 200 and 168 are both still in mild/moderate EPI (elastase <=200). Even scenario C isn’t very meaningful, even though there is an “increase”, this is still clearly EPI.
In most cases, the fluctuations in test results are likely a combination of both natural fluctuations in pancreas production and/or test reliability. If someone was eating a super low fat diet, taking enzymes effectively, that may influence how the pancreas is producing its natural enzymes – we don’t actually know what causes the pancreas to fluctuate the natural enzyme levels.
The only case that is meaningful in these examples is scenario D, where someone initially had a result of 112 and later clearly above the EPI threshold (e.g. 537). There are a few cases in the literature where people with celiac seem to have temporary EPI and later their elastase production returns to normal. This hasn’t been documented in other conditions, which doesn’t mean that it’s not possible, but we don’t know how common it is. It’s possible the first sample of 112 was due to a watery sample (e.g. during diarrhea) or other testing inaccuracy, too. If a third test result was >500, I’d assume it was a temporary fluctuation or test issue, and that it’s not a case of EPI. (Yay for that person!). If it were me (and I am not a doctor), I’d have them try out a period without enzymes to ensure that symptoms continued to be managed effectively. If the third test was anywhere around 200 or below, I’d suspect something going on contributing to fluctuations in pancreatic production and not be surprised if enzymes were continued to be needed, unless the cause could be resolved.
But what about scenario C where someone “went from severe to mild/moderate EPI”?!
A lot of people ask that. There’s no evidence in the hundreds (seriously, hundreds) of papers about EPI that indicate clearly that enzymes should be dosed based on elastase level, or that there’s different needs based on these different categories. The “categories” of EPI originally came from direct measurements of enzyme secretion via invasive tests, combined with quantitative measurements of bicarbonate and fat in stools. Now that fecal elastase is well established as a non-invasive diagnostic method, severities are usually estimated based on the sensitivity of these cutoffs for detecting EPI, and that’s it. The elastase level doesn’t actually indicate the severity of the experience through symptoms, and so enzymes should be dosed and adjusted based on the individual’s symptoms and their diet.
In summary:
- Elastase <=200 ug/g is very reliable, indicates EPI, and warrants starting PERT.
- There is one small study suggesting even people with elastase 200-500 might benefit from PERT, if they have symptoms, but this needs to be studied more widely.
- It’s possible clinicians are conflating the sensitivity and specificity, thus misunderstanding how accurately elastase tests can detect cases of mild/moderate EPI (when elastase is 100-200 ug/g).
—
Let me know if anyone has questions about elastase testing, sensitivity, and specificity that I haven’t answered here! Remember I’m not a doctor, and you should certainly talk with your doctor if you have questions about your specific levels. But make sure your doctor understands the research, and feel free to recommend this post to them if they aren’t already familiar with it: https://bit.ly/elastase-sensitivity-specificity








Recent Comments