When you’re diagnosed with celiac disease, it is nice in the sense that you have a known issue (consuming gluten causes an autoimmune reaction and damage to your body) and that the solution is known: eating 100% gluten free. The challenge, though, is that “being gluten free” is not easy. Every food, every drink, every morsel – and even some non-food items – can risk cross-contamination, even if something itself is gluten free. There are countless decisions a day about what is safe to eat. And what many people don’t realize (and may find confusing from the outside) is that this decision process can change, over time or even on a day to day or situational basis.
I had been thinking about writing a post about my approach to celiac and how I decide what is safe for me to eat (and why), and how that may differ from another person’s perspective. Even person to person with celiac, we may make different decisions! But more importantly, I myself may make different decisions on different days for the same food or situation. (Plus, people who are gluten free for non-celiac reasons may have their own, differing decision making process about gluten.) There was also recently a really interesting scientific study published that I think can help illustrate why decisions vary at different points in time for the same person, so I wanted to talk about the high level approach and then what this study shows us about why this type of approach is helpful for people with celiac. I have had celiac for 18+ years, so I have a lot of experience evaluating food options, food labels, and deciding what to do. I rarely get glutened – maybe once a year, if that – and this is even with eating out and getting takeout from a lot of restaurants. I am also very symptomatic (even tiny amounts of gluten are noticeable to me), thus I have some confidence in categorizing myself as someone who does not get glutened often. Disclaimer is probably needed though: I’m not a medical professional and I’m not telling you what to do. Instead, I’m trying to show you how I think and evaluate things:
- Eating certified gluten-free is best, but not always possible
It’s helpful to realize that there are certifications for gluten free. In the US (where I live), there are a couple of different labels to understand the difference for. A food labeled “gluten free” means it has been tested to the FDA standards of <20ppm. However, that doesn’t mean it’s certified. There are several GF certifications beyond this standard, most of which are to the standard of <10ppm, and usually brands that bother to get certified also have good processes for vetting ingredients (inputs) as well as batches (outputs) of products. Different certifications have different requirements for these things so they slightly vary, but usually it means a higher standard – meaning a lower amount of gluten tolerance – than a standard word of “GF” on the label.
That being said, it’s a lot better than NO indication of gluten free on a label!
My rough hierarchy is:
- Certified gluten free (usually <10ppm)
- Gluten free (FDA standards, so <20ppm)
- No indication of ‘gluten free’, but no gluten-containing ingredients and no cross contamination warning such as “made on shared equipment”. This means it could be <20ppm or could be above, we don’t know.
- No indication of ‘gluten free’ and a yellow flag – some cross contamination risk such as “made on shared equipment”; or a red flag “may contain wheat”. Again, we don’t know if it’s <20ppm or above.
- Red flag, will not eat for any reason – contains wheat or a gluten-containing ingredient (such as malt or malt flavoring, rye, barley, etc.)
There are a lot of foods that I eat that fall into that third category though – say, picking up a banana from the produce section at the grocery store. It isn’t labeled as gluten free – is it safe to eat? I say yes and choose to eat it, even though it’s not labeled, because it doesn’t make sense to have a gluten free label on a banana when it’s a self-contained item and not processed with other foods that are likely to contain gluten.
Same for more processed items, such as other fruits and vegetables, or a container of pre-washed and pre-cut fruits or vegetables, or even a bag of frozen vegetables. As long as it doesn’t have a “may contain wheat” warning on it, I am more likely to be ok consuming it if it doesn’t have gluten-containing ingredients.
But there are other foods that ARE an issue in this category, which I have learned from experience of reading a lot of food labels. Trail mix, processed fruit (like yogurt-covered and other dried fruit products), etc because they are often mixed on shared production lines with trail mix items that do contain wheat. For these, I am more likely to be cautious and avoid items that use shared equipment because it feels like the risk of cross contamination across product lines or batches is higher. (It’s a bummer, because it rules out a lot of dried fruit, trail mixes and snack mixes, nuts, etc. that otherwise should be gluten free, but for me the uncertainty is too high). Oat related products, which I’ll talk about more below, also fall into this category.
Generally, though, some brands or sellers of products aren’t incentivized to test and label their products GF, even if they ARE gf (bananas and other single-item fruits and veggies are a great example). But, given they themselves have no gluten ingredients and are minimally processed, they’re usually a reasonable choice (e.g. a banana). GF testing costs a lot of money, which is why brands may not do it, and why we as people with celiac have to decide how to deal with the fact that there are a lot of foods in this category that may be safe to eat. Ruling them out because they don’t meet the costly most stringent standards would drastically limit our options and mess with quality of life. If you’re newly diagnosed and trying to recover from months or years of immune system damage, it may make sense to be more strict at first, and then expand back out (or not). But know that some of us with celiac ARE choosing to eat foods that are not definitely labeled gluten free (such as a banana), and that does not necessarily mean we are getting glutened.
2. The amount of food matters
Because I am someone who gets symptoms from tiny amounts of gluten and know how much gluten hurts me, I have a clear red line: I don’t eat gluten. I will not knowingly eat “may contain wheat” products: for me, it’s not worth it, even if the risk of a single bite is low.
One example is a few months ago, when I was online grocery shopping and found a new product, a chocolate-covered frozen strawberry that was new to me. It didn’t list gluten ingredients on the label, but they didn’t have any cross contamination warnings in the product listing, on the picture of the item online, nor anything on the manufacturer’s website. So I bought it. When it arrived, I went to try some, and glanced at the back of the bag and saw a ‘may contain wheat’ warning. ARGH. I was so mad: I had actually cross-checked the manufacturer’s website before I bought it, in case the listing was wrong! I was mad enough to email the brand and tell them they should be listing this on their product site, plus the grocery store listings (even though they don’t always have control over that). But they DO control their site and they should fix that. Super annoying. Anyway, the point is, I didn’t eat these and gave them to my husband, Scott, because they weren’t worth a possible glutening. I could’ve tried one just to taste it, but it wasn’t worth that possible risk. Sloppy labeling and communication about labeling like that makes me not trust a brand.
But, as above, there are times when there are products with NO label / cross contamination warning…and I do try it. However, I recognize the risk could be higher in this product versus the example above (chocolate covered strawberries that may contain wheat) – and there’s no way to tell. The difference, though, often also has to do with whether the risk is known/not and the quantity. If I decided to try the chocolate covered strawberries, I’d likely mentally categorize them as safe and something I would keep eating, so I would consume more quantity of them, driving up the risk. Whereas if I “noped” them and put them in Scott’s gluten section of the freezer, I wouldn’t be at risk of mindlessly eating them at a later time in larger quantities, increasing the risk. For foods that are not labeled and don’t have a cross contamination warning, I usually am cautious about the quantity, because as the quantity consumed increases, the risk of consuming gluten also goes up.
And this is where that new scientific study comes in. They did a gluten challenge test via pills with celiac volunteers in Australia (shout out to these brave folks who participated in the study), and recorded symptoms *and* did a test for a proxy of immune activity to test response to multiple levels of gluten, from <1mg to 2mg, 3mg, and much higher doses. (It was randomized, blinded, and they also used a placebo for control!) And what they found was that doses <=2mg didn’t trigger an immune response…but 3mg did (in a sizable minority of participants). (Not necessarily symptoms though, even in those with an immune response). Note a HUGE caveat of this study is that immune response does not mean proven damage, but it does give us a threshold to understand at what point the body might start reacting and how to think about cumulative exposure over the course of day…for which we previously didn’t have the data to have a mental framework.
Thinking about 3mg is super duper helpful because we can now use that in context of the thresholds we are most familiar with: <10ppm (certified GF usually) and <20ppm (FDA standard for GF). If you eat 30g (a small snack) of a food that is <10ppm (parts per million, so < 10/1,000,000th of it is gluten), you get a possible 0.3mg gluten dose – which you wouldn’t expect an immune reaction to. Same for doubling that, a larger snack – that would be 0.6mg. But if you 10x that (think meal-size amount), that puts you at 3mg. Whoa. That’s the level of an immune response (possibly), if gluten was present at that top end (10ppm) for that product. Now, does that mean symptoms and damage long-term? Maybe not – but this starts to show us how the amount of food matters IN ADDITION to the labeling.
The FDA standard, <20ppm, shows this even more. A 30g food amount at the top end of the 20ppm standard would be a 0.6mg dose; a larger 60g snack would be 1.2mg…whereas a 10x meal size amount (eg 300g) would be 6mg, which is definitely in the category where the immune system is more likely to respond (according to that study).
Now imagine a food in my third category, unknown ppm. That means it could be even below certified standard (eg <10) or FDA standard (<20ppm), but it could also be more – we just don’t know. But in any case, use the same logic: 30g of 40ppm (double the FDA standard, for easy math) would mean 1.2mg. Maybe fine. But as the amount of food increases, you’ll see that possible gluten amount increase: 60g of food at 40ppm would be 2.4mg, and well before you get to a meal size (300g), you would go well beyond the point of gluten exposure (>=3mg) where more people experienced an immune response and – as the amount got bigger – also increasingly saw symptoms.
This is how I think about the label/not uncertainty and the amount of uncertainty, now: in context of the quantity I might want to eat. I had previously intuited “this is more risky” when the label was uncertain and the food quantity was bigger, but this helps me put a numerical framework on the risk.
Some loose categories to think about now with this framework:
- For naturally GF / simple or few-ingredient foods, like fruit, vegetables, plain rice, potatoes, beans, plain dairy, or rice pasta, “no gluten ingredients” may be enough for many routine decisions, especially if the product is simple and not from a high-risk category and does not have any cross-contamination label warnings.
- For complex processed foods, “no gluten ingredients” is weaker. A 30 g snack may still be a reasonable pragmatic choice for some people, but a 300 g meal is a different decision.
- For oat-containing foods, “no gluten ingredients” without GF labeling or process information is a much weaker signal. Oats deserve their own caution category because of cross-contact risk in the supply chain.
3. Oats are evil*
* Evil in the sense that they require their own mental category of gymnastics and special handling, above and beyond what we have discussed. Some people with celiac perceive that they are sensitive to oats themselves, but not everyone is – and I am not. I do eat oats, see below. But, oats are OFTEN cross-contaminated at harvesting, processing, etc because of the nature of being grown in fields near gluten-containing grains, and thus anything with oats is a hot mental mess of risk. (They’re not really evil, they just require a lot of thought, see below).
Oats are themselves gluten-free, but they have higher cross-contact risk from growing, transport, processing, and manufacturing. Whole or rolled oats prominent in the ingredient list should bump risk assessment up; a controlled gluten-free oat process with certification, purity protocol, dedicated facility, and batch testing should bump risk assessment down.
But sadly, some of this is really hard to figure out. It used to be that there were “purity protocol” oats, where oats were grown in fields far away from gluten, harvested separately, processed separately, transported separately, etc. And with more testing on arrival, etc. But this was very expensive, and it’s rare now. And…that process was still not flawless; sometimes cross contamination of oats still happened. (The site “Gluten Free Watchdog”, for example, which does lab testing on consumer GF products used to recommend certain brands of purity protocol oats, and as of 2026, no longer does so.)
So what is a person with celiac supposed to do? Avoid all oats?
You could, but you don’t have to. You could avoid oat-related products for any of the following reasons:
- Oats bother you for other reasons
- You are too tired to go check the brand and their product testing protocols for a particular product
- There’s no indication of testing for GF or special handling consideration even though it uses oats
You could also decide to consume oat-containing products for any of the following reasons:
- The product is certified gluten free, which means there are requirements around testing the ingredients and the batched products, which reduces the risk
- The product is one where oat is used for oat flour (meaning anything is ground up and distributed across the flour and then across products, so the risk of one bar/cookie/etc itself is lower than a whole oat product), lowering the risk of a particular bite having >3g of gluten on its own
- The product is not certified gluten free but the brand has publicly shared their process for testing batches of products and preferably how they test the oats themselves before using them inside products.
- YOLO and you want to eat whatever the product is anyway, regardless of the above
What do I do? It depends.
Sometimes, depending on the situation, I fall into scenario A (avoid) based on reason number 2: I am too darn tired to go research the provenance and figure out if 3 applies. It’s safer to avoid as a rule, and eat something else (or not eat, and eat later something safe).
Other times I will do the research and if it falls into reasons 1-3 of scenario B, I will choose to consume it.
Here are some practical examples, which ended up glutening me, and what I changed as a result, and some maybe surprising categories of things that I *do* eat as a person with celiac:
A. Remember Nature Valley Oat & Honey bars? I looooved those as a kid. So when KIND came out with oat&honey bars that were marked gluten free, I was excited. I avoided them for a while, but I heard other people with celiac were eating them, and I decided to try them. I did ok, but I did eat one once (when I didn’t have a lot of food options while traveling), and BOOM I was glutened. It was definitively that which glutened me and it was brutal. Those went back on the NOPE list for me, along with all other KIND products containing oats. Yes, they are marked ‘gluten free’ which means that they batch tested at FDA standard (<20ppm), but cross contamination can still happen, and it was such an extreme level that I permanently decided this was not a risk worth taking for me. (The exception might be if I was stranded on a desert island and that was the only food item; but even when very very hungry on a travel day I will choose staying hungry over trying one of those again, or anything else that is a similar whole-oat type product rather than something where the oat has been processed and spread as a flour. The latter reduces the risk more than whole-oat products)
B. Speaking of Nature Valley brand, recently I noticed a product listing for new chewy protein bars that were supposedly gluten free. I assumed the listing was wrong, because in my brain ‘nature valley’ is strongly associated with gluten. But, I double checked, and it’s actually certified gluten free. More importantly, I looked at the ingredients – these are specifically the chewy nut protein bars, and there are no oats, they are nut (and soy protein) and chocolate based). Ok. So I can apply my rubric – not the oat one – and because they’re certified gluten free, try them. I did (and actually like them), so these have entered my ‘snack bar’ rotation as a reasonable option. I wouldn’t eat a lot of them in one day – because the risk grows with quantity, but because they are certified gluten free, that is good enough for me at single-serving quantity. And so far, I have not gotten glutened from these.
C. But what about other oat-containing products? Because of my past experiences, I am VERY skeptical. A cousin-in-law shared a new product she thought I might like that she had gotten for her toddler, because it was marked GF. It was an oat-based PBJ-stuffed oat bar. I scoffed and dismissed it, because in the past I had checked out this brand and they didn’t say anything about GF processes and testing, so I let my oat rubric (NOPE) override the choice. However, when I had more energy (and was bored), I went and looked them up online. Nowadays, this brand DOES list their processes very clearly. They say they are GFCO-certified gluten-free, its oats are certified gluten-free, its bakery is a gluten-free facility, and it does daily testing on every batch of oat products. Ok, now we are talking! (They also talk about purity protocol oats, which as I said, is a great detail but does not make it infallible). But because they used gf-tested oats before they even start cooking AND do daily testing of batches, that means there is a greater chance of catching issues. This is important because one bar is a 60g serving, which is double a serving of my previous example…but it’s the certified (<10ppm) standard, so that means 60g of snack, even if it was 10ppm, means a likely 0.6mg of gluten exposure risk. That’s still well below the ~3mg immune response threshold, so that makes me more comfortable with the risk of this product. Plus, like I said, the in/out testing. Would I eat 5 of these in a day (300g of it)? No, the risk definitely goes up with more. But, I not only eat these, I eat these on a periodic basis (a few times a week), because of the testing and certification. Even though they are oat-based.
(What is this product/brand? Bobo’s PB&J rounds. I haven’t tried many other Bobo’s products but the above detail is supposed to apply to their other products, too – check their website and on-product labeling for the latest details in case this has changed.)
D. Another example might be Honey Nut Cheerios or Lucky Charms, which are now all GF by default. But they’re made with oat flour. General Mills has pretty good testing processes for batches, but they also had some kerfluffles when these products were first marketed as GF with feedback from the community that it was causing issues. Now that I have the above scientific study to help frame QUANTITY with risk, it makes me wonder if it was the quantity that was causing the issues, because cereal is hard to do a single-serving of, and as I’ve shown in the data above, as you eat more of something the risk goes up, EVEN IF IT IS CERTIFIED GF. A large bowl (or two) of cereal would be more likely to get increasing exposure, even if the per-serving amount was under the FDA standard or certification threshold of acceptable ppm. I personally also have a hard time limiting my quantities of cereal, so based on this I don’t eat oat-based cereal like this…but recently I decided I could get single-serving cups of Lucky Charms occasionally, because it’s a fixed quantity (30g); labeled as GF; and it’s an oat flour product rather than whole-oats. Plus General Mills has made it clear they test after sifting their oats; after the oats become flour; ship oat flour separately; then they also do batch testing at the end. (Same for other General Mills GF oat flour products). Like Bobo’s, that’s as decent of a process that I think we can probably get. So, like Bobo’s, I am now willing to eat these products. But, again, for cereal, only as a single-snack-serving product, because of the risk quantity calculation and my own experience with resisting the temptation of a larger bowl of cereal.
E. I even eat oatmeal. Quaker Oats, like General Mills, has a process where they evaluate oats in a separate facility for gluten as well as evaluate their batches of finished products. Note that this does not mean the general Quaker Oats products: they only have a few GF products. One is a big can of quick oats (like you might use in recipes for say, oatmeal chocolate chip cookies), and another is prepared packets that you mix with water or milk to make a bowl of oatmeal. These GF versions with prepared packets come in plain or maple & brown sugar flavors, and I eat the latter periodically and have never gotten glutened from these. Like the cereal, I make this decision based on the brand’s processes and testing of input ingredients as well as batch testing the products, plus the awareness that there is still a risk but that I am further mitigating this risk by consuming single-serving quantities of it.
—
All of the above is a lot of words but this chart may help, with colors to show how as you go down the levels of labeling certainty, the type of product (the three columns: simple; complex processed; oat containing) also should factor in, AND so should the quantity because the risk goes up the more you eat something.
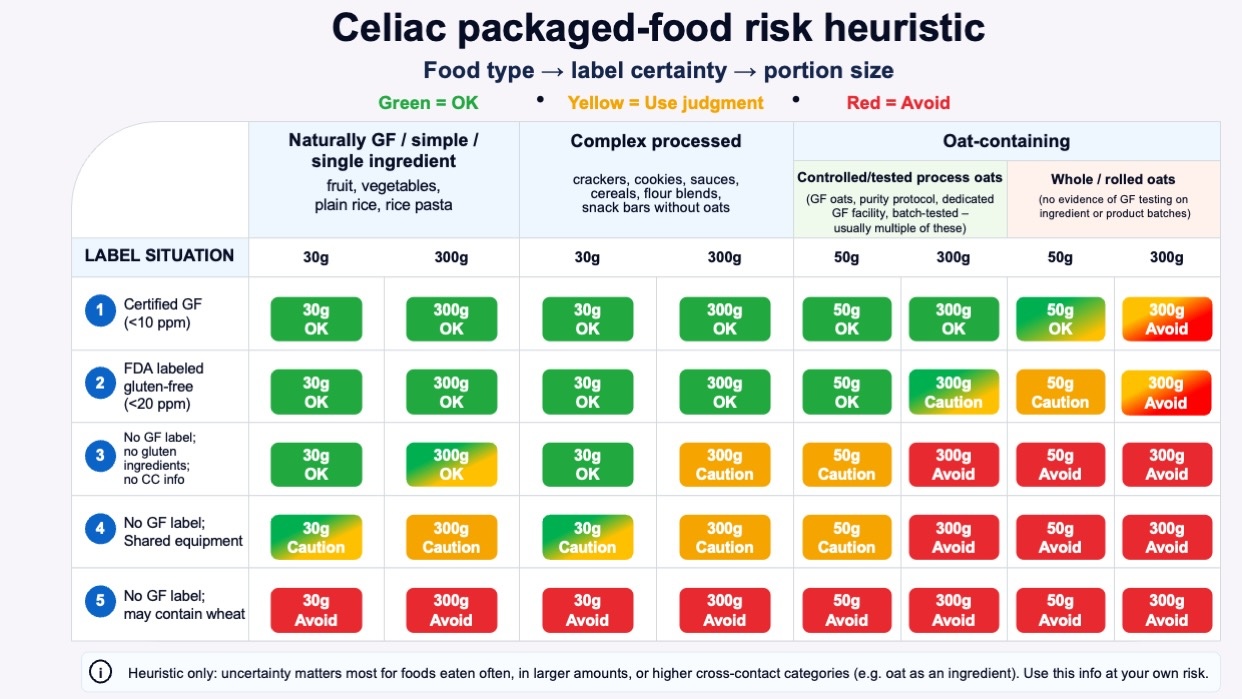
It’s absolutely ok to make different decisions at different points in time, based on the situation. If you are struggling with recovering after diagnosis, you may want or need to be more careful and limited in what you eat. If you have been getting glutened and can’t figure out where, this may help you think through types of food or quantities where the risk may be in the quantity. (P.S. – people with celiac can also have exocrine pancreatic insufficiency (known as EPI or PEI), so be aware if you have eliminated all sources of gluten and still have GI symptoms, you may want to take the EPI/PEI-SS and ask your gastroenterologist and discuss elastase testing to rule out EPI).
And sometimes you’re just too tired to think through the risk and just stick with the safest possible option – meaning only choosing the things labeled definitively GF. That’s fine, too. You can also choose differently when you have more energy to do research and find out if you should rule something permanently out or rule it back in if the brand has changed their labeling / processes /etc.
Personally, if I’m put on the spot (meaning someone offers me food or shows me a label and asks me if I want any), if there is any uncertainty I’m prone to saying no thanks, it’s not worth it (right then). Sometimes I’ll go back later when I’m not on the spot and look it up and look for more information about testing/etc from the brand. That’s how I ended up adding the PB&J rounds into my snack rotation, after first excluding them because they failed my oat rubric test based on the on-product label.
Another big caveat is to remember to check products often, even if it’s something you eat often. Brands could add more testing and validation to their products; they can also change their products and add new cross contamination warnings to their products that weren’t there before. Anything that is processed is definitely worth reading the label for: I have found that cheap store-brand bags of frozen vegetables usually have “may contain wheat” warnings on them (argh!) on the product itself, even though the online pictures of it and the label don’t show them online. So keep in mind online listing and online pictures and actual on-product labels can vary. (Name brand frozen veggies tend to not have this warning on them, so in that scenario I would pay more (sigh) for the name brand without the warning).
 And again, I want to emphasize that you can make difference decisions for different situations. How I decide – and my rubric above – may not match how you handle things. Everyone is different. If you’ve been glutened lately and want to be more strict/careful in your decision-making, you can. If you are traveling and don’t want to risk feeling bad, you can be more stringent in your criteria for what you do/don’t risk. These are just a few examples of where I make varying decisions at any point in time.
And again, I want to emphasize that you can make difference decisions for different situations. How I decide – and my rubric above – may not match how you handle things. Everyone is different. If you’ve been glutened lately and want to be more strict/careful in your decision-making, you can. If you are traveling and don’t want to risk feeling bad, you can be more stringent in your criteria for what you do/don’t risk. These are just a few examples of where I make varying decisions at any point in time.
—
Disclaimer is probably worth repeating: I’m not a medical professional, I’m just a person with celiac for 18+ years, I am not telling you what to do, but this reflects how I handle uncertainty and decision making and how/why it changes over time, especially as someone who eats a lot of packaged and prepared foods.




 The point isn’t convincing you to want to use my app. Most people don’t have a use case for this. But I want more people to build the patterns of recognizing when their feelings are trying to tell them something (e.g. this is a problem we could work on improving, even if it is not solvable) and build the skills of identifying when this is a software-shaped feeling. Especially when we are dealing with health-related situations and especially chronic non-curable diseases, and especially ones with treatments or medications that are not fun, it is so important to solve friction and frustration whenever and wherever we can. Not everything is a software-shaped feeling, but the more we recognize and address, the better off we are. Or at least I am, and I hope to help others do the same.
The point isn’t convincing you to want to use my app. Most people don’t have a use case for this. But I want more people to build the patterns of recognizing when their feelings are trying to tell them something (e.g. this is a problem we could work on improving, even if it is not solvable) and build the skills of identifying when this is a software-shaped feeling. Especially when we are dealing with health-related situations and especially chronic non-curable diseases, and especially ones with treatments or medications that are not fun, it is so important to solve friction and frustration whenever and wherever we can. Not everything is a software-shaped feeling, but the more we recognize and address, the better off we are. Or at least I am, and I hope to help others do the same.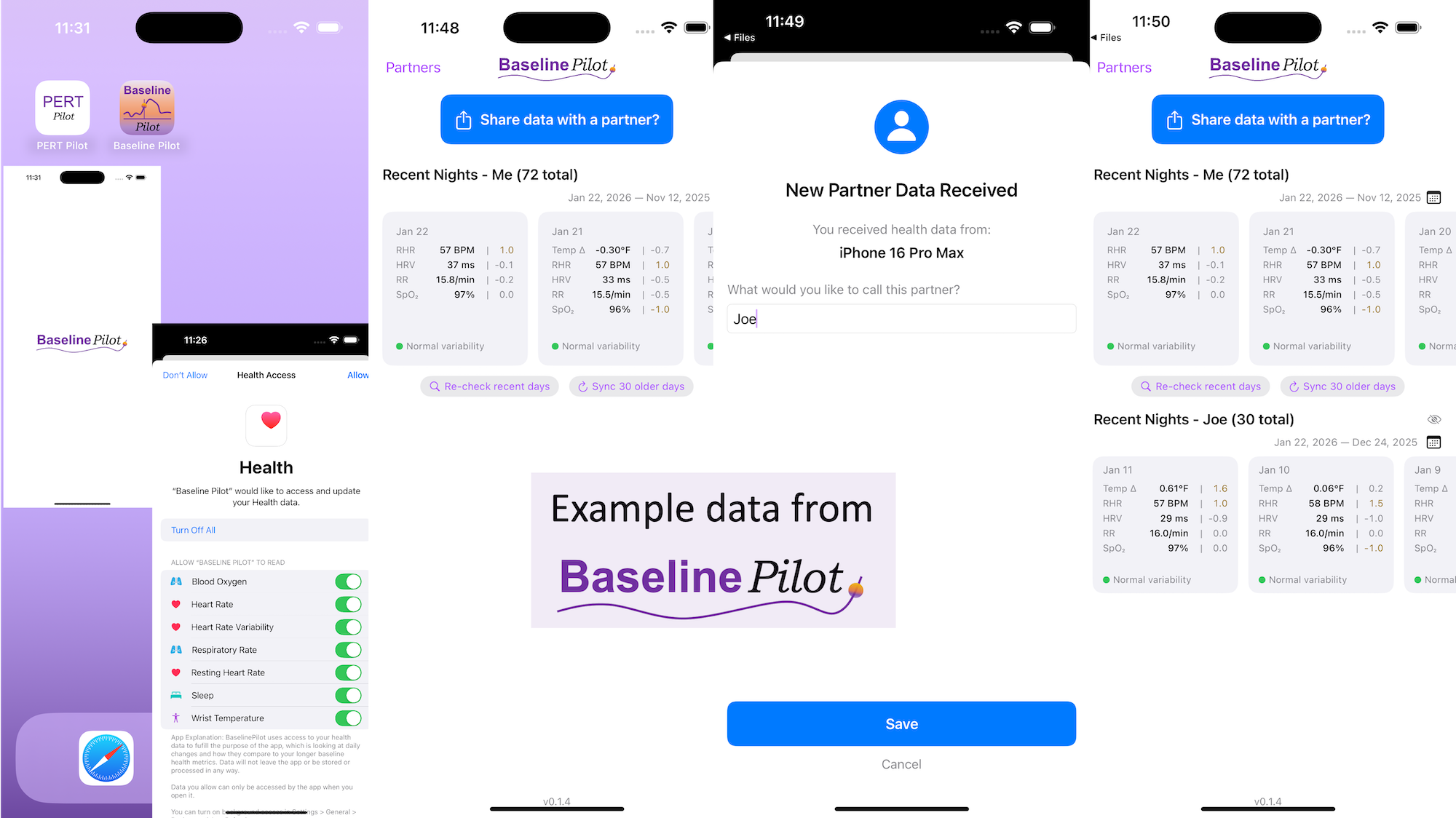
 All of this data is local to the app and not being shared via a server or anywhere else. It makes it quick and easy to see this data and easier to spot changes from your normal, for whatever normal is for you. It makes it easy to share with a designated person who you might be interacting with regularly in person or living with, to make it easier to facilitate interventions as needed with major deviations. In general, I am a big fan of being able to see my data and the deviations from baseline for all kinds of reasons. It helps me understand my recovery status from big endurance activities and see when I’ve returned to baseline from that, too. Plus the spotting of infections earlier and preventing spread, so fewer people get sick during infection season. There’s all kinds of reasons someone might use this, either to quickly see their own data (the Vitals access problem) or being able to share it with someone else, and I love how it’s becoming easier and easier to whip up custom software to solve these data access or display ‘problems’ rather than just stewing about how the standard design is blocking us from solving these issues!
All of this data is local to the app and not being shared via a server or anywhere else. It makes it quick and easy to see this data and easier to spot changes from your normal, for whatever normal is for you. It makes it easy to share with a designated person who you might be interacting with regularly in person or living with, to make it easier to facilitate interventions as needed with major deviations. In general, I am a big fan of being able to see my data and the deviations from baseline for all kinds of reasons. It helps me understand my recovery status from big endurance activities and see when I’ve returned to baseline from that, too. Plus the spotting of infections earlier and preventing spread, so fewer people get sick during infection season. There’s all kinds of reasons someone might use this, either to quickly see their own data (the Vitals access problem) or being able to share it with someone else, and I love how it’s becoming easier and easier to whip up custom software to solve these data access or display ‘problems’ rather than just stewing about how the standard design is blocking us from solving these issues!
 I haven’t open-sourced BookPilot yet, but I can (
I haven’t open-sourced BookPilot yet, but I can ( I know some of the answers to the question of why clinicians aren’t doing this. But, the question I asked the Stanford AI+Health audience was to consider why we focus so much on informed consent for taking action, but we ignore the risks and negative outcomes that occur when not taking action.
I know some of the answers to the question of why clinicians aren’t doing this. But, the question I asked the Stanford AI+Health audience was to consider why we focus so much on informed consent for taking action, but we ignore the risks and negative outcomes that occur when not taking action. Like using the Pro, having the Hypershell X Ultra makes it so I could do this full hike. It’s not a short hike: the full Rattlesnake Mountain hike is marked as 10.2 miles but from parking lot to parking lot it is closer to 10.9 miles and I tracked over 3,000 feet of elevation gain. I could do “just” the Rattlesnake Ledges hike (4.3 miles round trip, ~1100 feet of elevation gain), I could do the other side, but my muscles would be too fatigued to safely do a 10+ mile hike, so we wouldn’t even try it without an exoskeleton. And, there’s no way I would have considered doing it alone. Which…I did!
Like using the Pro, having the Hypershell X Ultra makes it so I could do this full hike. It’s not a short hike: the full Rattlesnake Mountain hike is marked as 10.2 miles but from parking lot to parking lot it is closer to 10.9 miles and I tracked over 3,000 feet of elevation gain. I could do “just” the Rattlesnake Ledges hike (4.3 miles round trip, ~1100 feet of elevation gain), I could do the other side, but my muscles would be too fatigued to safely do a 10+ mile hike, so we wouldn’t even try it without an exoskeleton. And, there’s no way I would have considered doing it alone. Which…I did!

 TL;DR: I love exoskeletons, they’re an instrument of freedom. I paid $1,200 in August 2025 for a Hypershell X Pro exoskeleton and love it (still love it). In late October/early November, I was given for free a Hypershell X Ultra exoskeleton after being selected for the Hypershell X Ultra Product Explorer program and have been using it and comparing it for the last several weeks. I love the opportunity and appreciate being chosen in the explorer challenge program so I could try it, and because it motivated me to head out on a big chicken-and-fox adventure up and over the full length of Rattlesnake Mountain, which I wouldn’t be able or willing to do without an exoskeleton to support my adventuring.
TL;DR: I love exoskeletons, they’re an instrument of freedom. I paid $1,200 in August 2025 for a Hypershell X Pro exoskeleton and love it (still love it). In late October/early November, I was given for free a Hypershell X Ultra exoskeleton after being selected for the Hypershell X Ultra Product Explorer program and have been using it and comparing it for the last several weeks. I love the opportunity and appreciate being chosen in the explorer challenge program so I could try it, and because it motivated me to head out on a big chicken-and-fox adventure up and over the full length of Rattlesnake Mountain, which I wouldn’t be able or willing to do without an exoskeleton to support my adventuring.
Recent Comments