tl;dr – No, they’re not here yet, but this is coming soon! Yay for new & more hardware options! See here to pre-order an Explorer HAT, eta of April 2018
—
Over the years, people have had a lot of awesome ideas on how
to improve the hardware that can be used with DIY closed looping. One such example, Oskar’s work with mmeowlink, led us to later work on smaller computer boards with built-in radio stick, aka the Edison/Explorer Board rig. We started working on that last fall; they were produced and available around November, and the community has been using those widely ever since.
However, like all things, the Edison/Explorer is not without it’s downsides. One of which is – there’s no screen. You historically have needed to plug in cables, or remote login to the rig, or have connectivity via your phone, to see what it’s doing. Sometimes this is more annoying than others.
Patrick Kelly, who has a daughter with T1D and began experimenting with OpenAPS, was one of the folks who wanted a screen on the rig. He suggested the idea, which Scott and I thought was awesome – but we don’t have the expertise to build that kind of hardware. Luckily, Patrick and his dad Jack Kelly, *do* have that expertise! They began exploring some of the options around creating a rig with a screen.
(This is one of my favorite parts of the OpenAPS community, where people bring in various types of expertise and we’re all able to collaborate to make everything from hardware and software and usability improvements!)
And at the same time…the rumors became reality, and we learned that Intel has decided to discontinue the Edison module. SAD PANDA. (Intel, if you’re reading this, please bring it back! We love the Edison!) That expedited the need to find the next generation hardware. Luckily, Patrick and Jack had been progressing on the screen, focusing on incorporating it into a “HAT” (board) for the Raspberry Pi. So after discussion with others in the community about pros/cons and availability about various other computing options other than the Pi, given the widespread availability of different types of Pi’s, we’ve decided to move forward with the Pi and a HAT (board) being the most usable option for the next round of hardware that we’ll be recommending to the community.
What exactly does a Pi HAT look like?
I’m so glad you asked 😉 Here is the Pi HAT with screen on a “Pi Zero W” (which I sometimes type as “Pi0” or “Pi 0”) and a “Pi 3” (pi three), compared to the Edison/Explorer Board. My trusty Chapstick is my unit of measurement, but given some of my international friends claim to not understand that yardstick, I threw in some Euro coins on the right as another measurement stick .;)

The Pi 0 is flipped on it’s back like a turtle – but the same Pi HAT can be used for the Pi 0 and the Pi 3. The HAT is bigger than the Pi so the radio stick doesn’t get blocked.
It’s the same radio as the Edison-based Explorer block, so same expected range.
What’s the point of the screen?
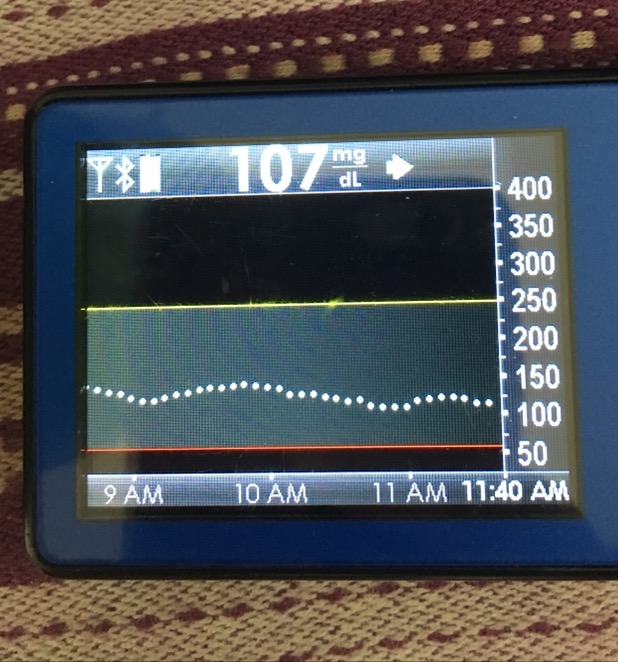
With a screen, you can easily see the logs of what the loop is doing: 
YOU CAN EASILY ADD AN OPEN WIFI NETWORK ON THE GO! (Yea, that all caps was intentional! :)). You can also see which wifi network it is on, check for IP address, etc.
 We’re still working on adding to the menus and playing around with what’s possible and what’s worthwhile for displaying on the menus by default.
We’re still working on adding to the menus and playing around with what’s possible and what’s worthwhile for displaying on the menus by default.
You can do all kinds of fun stuff – which Scott found out after asking me one day, “what else should we add to the menu?” and I promptly said “a unicorn”. Scott said, “these don’t have emoji’s, though”.
Five minutes later, we have a DIY diabetes/OpenAPS unicorn built in ASCII, because why not? 😉

Ahem. Back to technical topics.
How is this board/HAT going to be made and when is it going to be available?
Like the Edison-based Explorer, the Pi’s Explorer HAT is an open source hardware design, and ERD (who sold the Explorer for the Edison) will also be doing the Pi HAT.
Timeline is not 100% nailed down yet, but it will probably be another month or so. (Which is about a year after the Edison Explorer was first ready…crazy how time flies in the open source community!) We’ll of course, as always, shout from the rooftops when it’s ready for ordering & experimenting with. We’ll also be updating the OpenAPS docs to reflect the new gear recommended to buy, the steps for getting it up and running, troubleshooting, etc.
What about Edison/Explorer boards? Will that rig type still be supported by OpenAPS? Should I get any more of those?
Yep. Edison/EB will still be supported & widely used. There are some still left.
- But – if you already have an Edison/EB rig – I would make your next rig purchase a HAT for one of the Pi’s.
- If you’re new to the OpenAPS community and supply still exists, I’d still consider grabbing the parts for an Edison/Explorer rig – they’re still great, and we’ll continue to use the ones we have for a long time, and will still be supported in documentation. But you’ll likely want a HAT for a Pi rig of some sort, too, to take advantage of the screen & all the features that go with that for ease of use.
What about battery life for the Pi0/Pi3? How fast does it run? AND YOU HAVEN’T ANSWERED ALL OF MY OTHER QUESTIONS?!?!
One of the downsides of our (Scott/my) approach of getting everything to the community as fast as possible – both hardware and software – means that sometimes (every time) we share things that are works in progress. (And we are testing a whole lot of stuff on software, too.) The new hardware is no different. We don’t have all the answers yet, and we’ll hope you’ll help us figure things out as we go! Here’s some of the pending questions we have:
- Cost. (Pi’s are cheaper than Edison’s. Explorer HATs with screens are slightly more expensive. However, we’re expecting in sum that the HAT+screen rigs with Pi of choice will likely be cheaper than an Edison/Explorer.)
- Battery life. We know the Pi0 itself is not as efficient as the Edison, so it’ll likely require a bigger battery for the same run time. (No idea exactly how much bigger because I’m not using these rigs in the real world 100% of time yet, because…)
- Some Pi optimizations still need to be done. (The current code works just fine on a Pi3, but the Pi0 needs some optimization work done. The Pi 0, as you can see from the picture, is smaller, and will likely be the ‘mobile’ rig for many folks, while the Pi 3 might be a backpack/home rig.)
- Other options for “HATs” that don’t have a screen. (Eric has also been prototyping another Pi HAT, that doesn’t have a screen, and it’ll be great to test and see how that works as a potential option, too. Hop into the openaps/hardware-dev channel to chat with him if you have questions about his approach. )
As we work on the optimizations (great place to dive in if you’re looking for a place to help out!) and updating the scripts and the docs to reflect the Pi suite of options, I’ll begin carrying this kind of rig and doing my usual break-everything-in-the-real-world-and-fix-all-the-things testing approach.
—
I’m excited. It’s so great to have this kind of collaboration with expertise in so many areas, with everyone centered on the goal of making life with diabetes easier and safer! Shout out to the Kelly family & their colleagues for all the work on the screen & HATs; to Scott for a lot of development work on both hardware and software side; to Morgan & ERD for continuing to be a part of making great open hardware more widely available; and many other people who are working on bits and pieces to make everything possible!
—
January 2018 update: rigs are still evolving! You can pre-order an Explorer HAT, eta of shipping is April 2018.
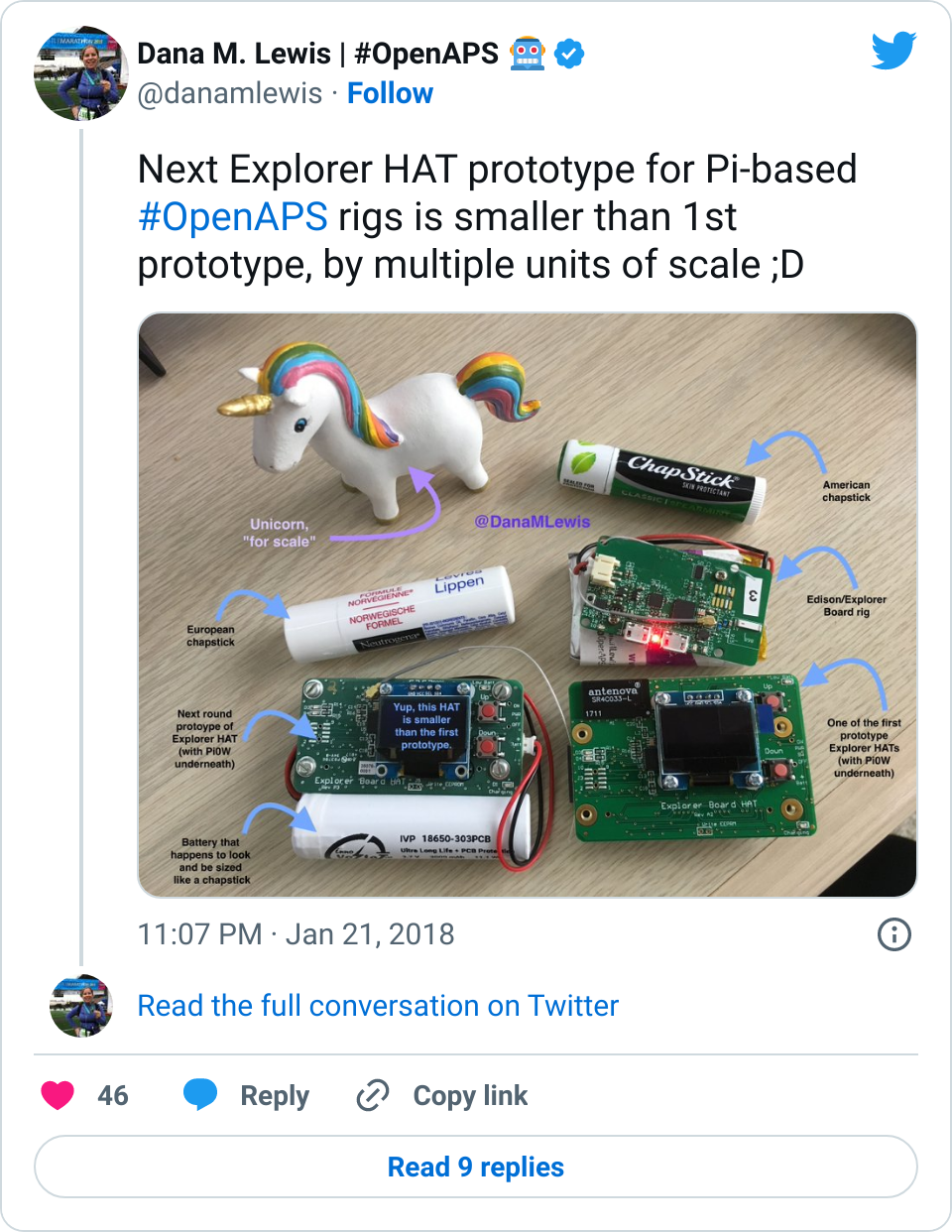
See the openaps-menu software code here; and the Explorer HAT hardware repo is here.















Recent Comments