Nobody appeared to notice the other day when I tweeted about going through airport security with 13 pieces of adhesive on my body. Which is amusing to me, because normally I sport two: my insulin pump site, and my continuous glucose monitor (CGM) sensor. That particular day, I added another diabetes-related piece of adhesive (I was giving the Freestyle Libre, a flash aka not quite continuous glucose monitor, a try), and 10 pieces of adhesive not directly related to diabetes. Or maybe, it will be in the future – and that’s what I’m trying to figure out!
—
Last fall, my program officer from RWJF (for my role as PI on this RWJF-funded grant – read more about it here if you don’t know about my research work) made an introduction to a series of people who may know other people that I should speak to about our project’s work. One of these introductions was to a researcher at UCSD, Todd Coleman. I happened to be in San Diego for a meeting, so my co-PI Eric Hekler and I stopped by to meet Todd. He shared about his lab’s work to develop an ambulatory GI sensor to measure gastric (stomach) activity and my brain immediately started drooling over the idea of having a sensor to better help assess our methods in the DIY closed looping community for articulating dynamic carb absorption, aka how slow or fast carbs are absorbing and therefore impacting blood glucose levels. I took over part of the white board in his office, and started drawing him examples of the different data elements that we have #OpenAPS (my DIY hybrid closed loop “artificial pancreas”) calculate every 5 minutes, and how it would be fantastic to wear the GI sensor and graph the gastric activity data alongside this detailed level of diabetes data.
I immediately was envisioning a number of things:
- Assessing basic digestion patterns and figuring out if the dynamic carb absorption models in OpenAPS were reasonable. (Right now, we’re going off of observations and tweaking the model based on BG data and manual carb entry data from humans. Finding ways to validate these models would be awesome.)
- Seeing if we can quantify, or use the data to better predict, how post-meal activity like walking home after dinner impacts carb absorption. (I notice a lot of slowed digestion when walking home from dinner, which obviously impacts how insulin can and should be dosed if I know I’ll be walking home from dinner or not. But this is something I’ve learned from a lot of observation and trial and error, and I would love to have a more scientific assessment of this impact).
- Seeing if this could be used as a tool to help people with T1D and gastroparesis, since slowed digestion impacts insulin dosing, and can be unpredictable and frustrating. (I knew gastroparesis was “common”, but have since learned that 40-50% of PWDs may experience gastroparesis or slowed digestion, and it’s flabbergasting how little is talked about in the diabetes community and how few resources are focused on coming up with new strategies and methods to help!)
- Learning exactly what happens to digestion when you have celiac disease and get glutened.
- Etc.
Fast forward a few months, where Todd and his post-doctoral fellow Armen Gharibans, got on a video call to discuss potentially letting me use one of their GI sensors. I still don’t know what I said to convince them to say yes, but I’m thrilled they did! Armen shipped me one of the devices, some electrodes, and a set of lipo batteries.
Here’s what the device looks like – it’s a 3D printed gray box that holds an open source circuit board with connectors to wearable electrodes. (With American chapstick and unicorn for scale, of course.)

And here’s what it looked like on me:

The device stores data on an SD card, so I had many flash backs to my first OpenAPS rig and how I managed to bork the SD cards pretty easily. Turns out, that’s not just a Pi thing, because I managed to bork one of my first EGG SD cards, too. Go figure!

And this device is why I went through airport security the other day with 10 electrodes on. (I disconnected the device, put it in my bag alongside my OpenAPS rigs, and they all went through the x-ray just fine, as always.)
Just like OpenAPS, this device is obviously not waterproof, and neither are the electrodes, so there are limitations to when I can wear it. Generally, I’ve been showering at night as usual, then applying a fresh set of electrodes and wearing the device after that, until the next evening when I take a shower. Right now, hard core activity (e.g. running or situps) generates too much noise in the stomach for the data to be usable during those times, so I’ve been wearing it on days when I’ve not been running and when I’ve not been traveling so Scott can help me apply and connect the right electrodes in the right places.
This device is straight from a lab, too, so like with #OpenAPS I’ve been an interesting guinea pig for the research team, and have found even low-level activity like bending over to put shoes on can trigger the device’s reset button. That means I’ve had to pay attention to “is the light still on and blinking” (which is hard since it’s on my abdomen under my shirt), so thankfully Armen just shipped me another version of the board with the reset button removed to see if that makes it less likely to reset. (Resetting is a problem because then it stops recording data, unless I notice it and hit the “start recording” button again, which drives me bonkers to have to keep looking at it periodically to see if it’s recording.) I just got the new board in the mail, so I’m excited to wear it and see if that resolves the reset problem!
—
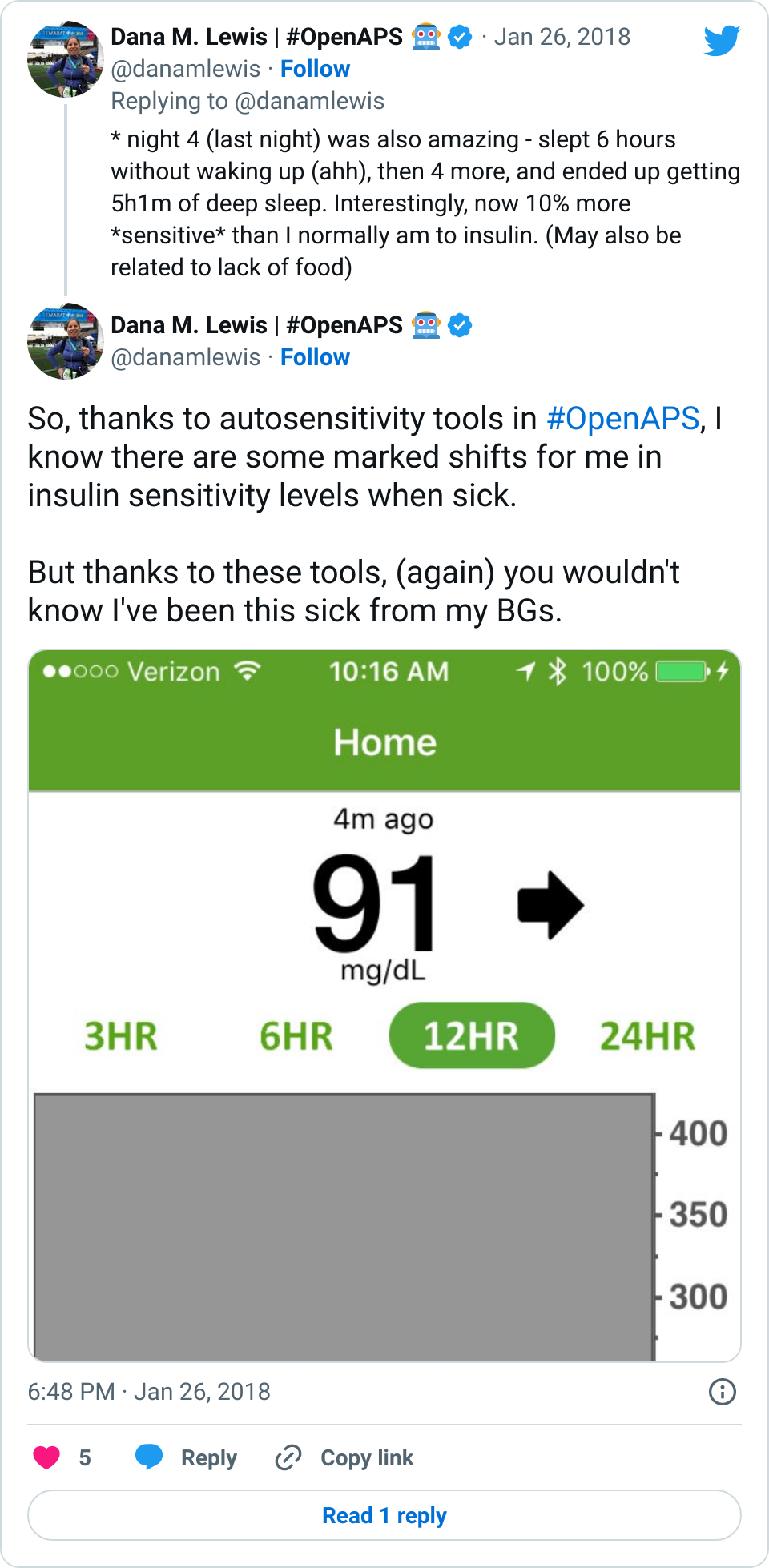
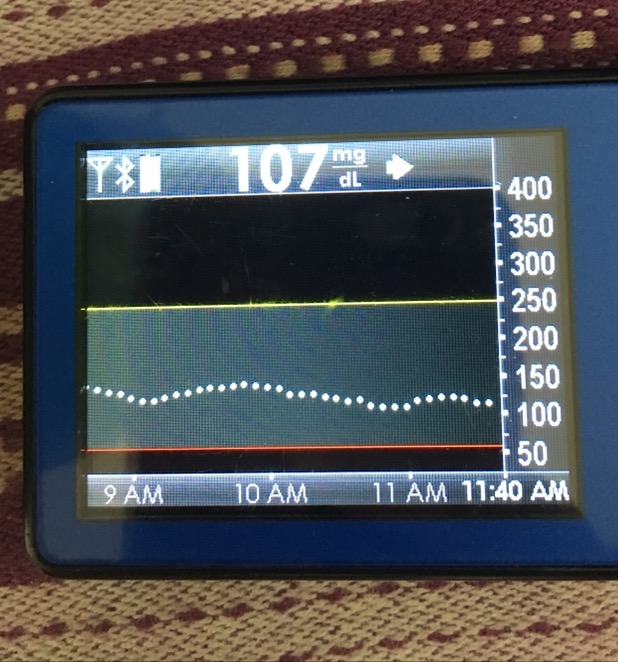
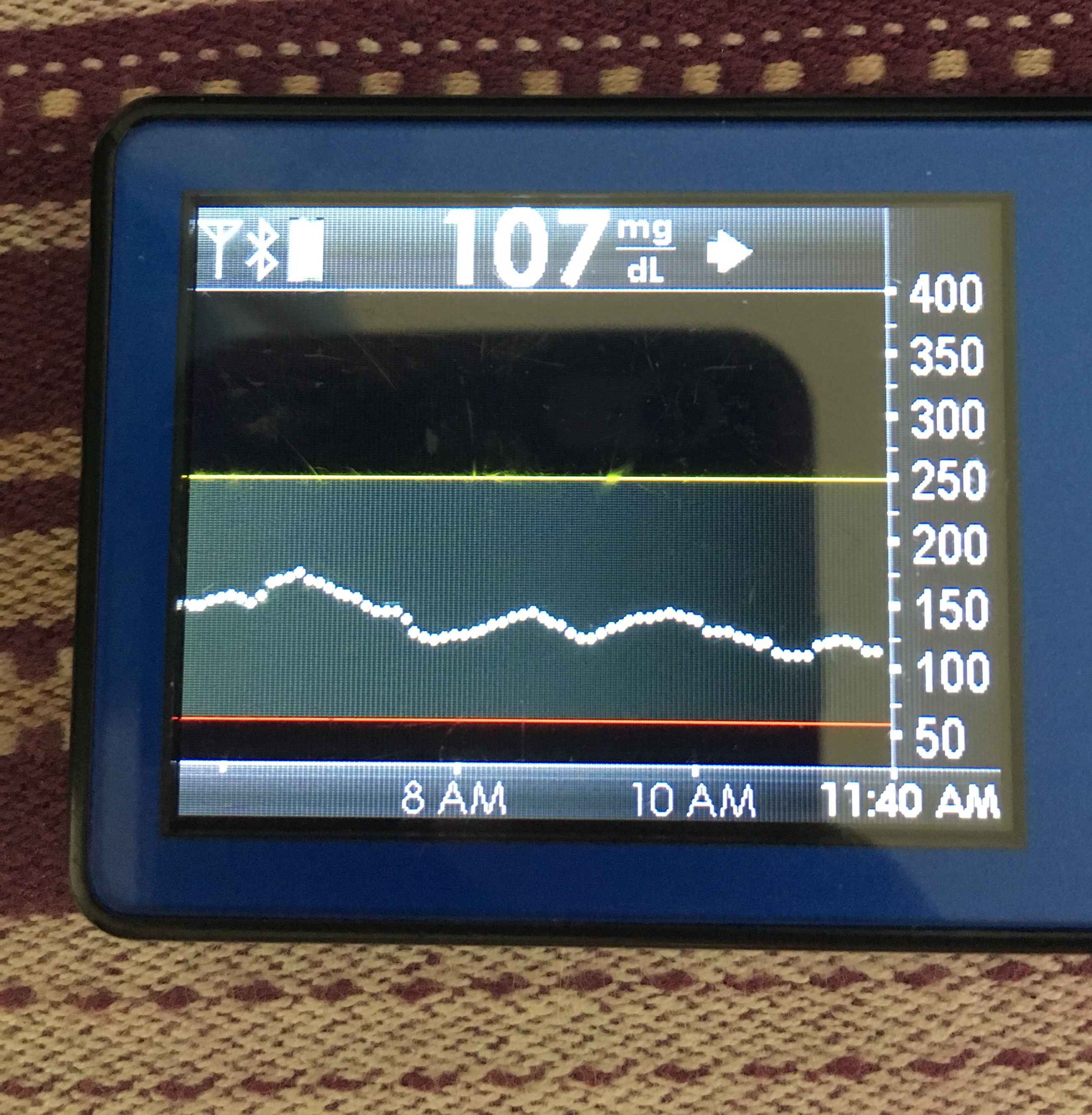
Data-wise, it’s been fascinating to get a peek into my stomach activity and compare it to the data I have from OpenAPS around net insulin activity levels, dynamic carb absorption activity, expectations on what my BG *should* be doing, and what actually ended up happening BG-wise. I wore it one night after a 4 mile run followed by a big dinner, and I had ongoing digestion throughout the night, paired with increased sensitivity from the run so I needed less insulin overall despite still having plenty of digestion happening (and picture-perfect BGs that night, which I wasn’t expecting). I only have a few days worth of data, but I’m excited to wear it more and see if there are differences based on daily activity patterns, the influences of running, and the impact of different types of meals (size, makeup of meal, etc).
—
A huge thanks to Todd, Armen (who’s been phenomenal about getting me the translated GI data back in super fast turnaround time), and the rest of the group that developed the sensor. They just put out a press release about a publication with data from one of their GI studies, and this press release is a great read if you’re curious to learn more about the GI sensor, or this news piece. I’m excited to see what I can learn from it, and how we can potentially apply some of these learnings and maybe other non-diabetes sensors to help us potentially improve daily diabetes management!








Recent Comments