If you’ve scoffed at, dismissed, or tried using AI and felt disappointed in the past, you’re not alone. Maybe the result wasn’t quite right, or it missed the mark entirely. It’s easy to walk away thinking, “AI just doesn’t work.” But like learning any new tool, getting good results from AI takes a little persistence, a bit of creativity, and the willingness to try again. Plus an understanding that “AI” is not a single thing.
AI is not magic or a mind reader. AI is a tool. A powerful one, but it depends entirely on how you use it. I find it helpful to think of it as a coworker or intern that’s new to your field. It’s generally smart and able to do some things, but it needs clear requests and directions on what to do. When it misses the mark, it needs feedback, or for you to circle around and try again with fresh instructions.
If your first attempt doesn’t go perfectly, it doesn’t mean the technology is useless, just like your brand new coworker isn’t completely useless.
Imperfect Doesn’t Mean Impossible
One way to think of AI is that it is a new kitchen gadget. Imagine that you get a new mini blender or food processor. You’ve never made a smoothie before, but you want to. You toss in a bunch of ingredients and out comes…yuck.
Are you going to immediately throw away the blender? Probably not. You’re likely to try again, with some tweaks. You’ll try different ingredients, more or less liquid, and modify and try again.
I had that experience when I broke my ankle and needed to incorporate more protein in my diet. I got a protein powder and tried stirring it into chocolate milk. Gross. I figured out that putting it in a tupperware container and shaking it thoroughly, then leaving it overnight, turned out ok. Eventually when I got a blender, I found it did even better. But the perfect recipe for me ended up being chocolate milk, protein powder, and frozen bananas. Yum, it made it like a chocolate milkshake texture and I couldn’t tell there was powder in it. But I still had to tweak things: shoving in large pieces of frozen bananas didn’t work well with my mini blender. I figured out slices worked ok, and eventually Scott and I zeroed in that it was most efficient to slice the banana and put it into the freezer, that way I had ready-to-go frozen right-sized banana chunks to mix in.
I had some other flops, too. I had found a few other recipes I liked to do without protein powder. Frozen raspberry or frozen pineapple + a crystal light lemonade packet + water are two of my hot weather favorites. But one time it occurred to me to try the pineapple recipe with protein powder in it… ew. That protein powder did not go well with citrus. So I didn’t make that one again.
AI is like that blender. If the result isn’t what you wanted, you should try:
- Rewriting your prompt. Try different words, try giving it more context (instructions).
- Give it more detail or clearer instructions. “Make a smoothie” is a little vague; “blend chocolate milk, protein powder, and frozen banana” is a little more direction to tell it what you want.
- Try a different tool. The models are different for LLMs, and the setup is different for every tool. How you might use ChatGPT to do something might end up being different for using Gemini or MidJourney.
Sometimes, small tweaks make a big difference.
If It Doesn’t Work Today, Try Again Tomorrow (or sometime in the future)
Some tasks are still on the edge of what AI can do in general, or a particular model at that time. That doesn’t mean they’ll always be unable to do that task. AI is improving constantly, and quickly. What didn’t work a few months ago might work today, either in the same model or a new model/tool.
 I’ve started making a list of projects or tasks I want to work on where the AI isn’t quite there yet and/or I haven’t figured out a good setup, the right tool, etc. A good example of this was when I wanted to make an Android version of PERT Pilot. It took me *four tries* over the course of an entire year before I made progress to a workable prototype. Ugh. I knew it wasn’t impossible, so I kept coming back to the project periodically and starting fresh with a new chat and new instructions to try to get going. In the course of a year, the models changed several times, and the latest models were even better at coding. Plus, I was better through practice at both prompting and troubleshooting when the output of the LLM wasn’t quite what I wanted. All of that over time added up, and I finally have an Android version of PERT Pilot (and it’s out on the Play Store now, too!) to match the iOS version of PERT Pilot. (AI also helped me quickly take the AI meal estimation feature from PERT Pilot, which is an app for people with EPI, and turn it into a general purpose app for iOS called Carb Pilot. If you’re interested in getting macronutrient (fat, protein, carb, and/or calorie) counts for meals, you might be interested in Carb Pilot.)
I’ve started making a list of projects or tasks I want to work on where the AI isn’t quite there yet and/or I haven’t figured out a good setup, the right tool, etc. A good example of this was when I wanted to make an Android version of PERT Pilot. It took me *four tries* over the course of an entire year before I made progress to a workable prototype. Ugh. I knew it wasn’t impossible, so I kept coming back to the project periodically and starting fresh with a new chat and new instructions to try to get going. In the course of a year, the models changed several times, and the latest models were even better at coding. Plus, I was better through practice at both prompting and troubleshooting when the output of the LLM wasn’t quite what I wanted. All of that over time added up, and I finally have an Android version of PERT Pilot (and it’s out on the Play Store now, too!) to match the iOS version of PERT Pilot. (AI also helped me quickly take the AI meal estimation feature from PERT Pilot, which is an app for people with EPI, and turn it into a general purpose app for iOS called Carb Pilot. If you’re interested in getting macronutrient (fat, protein, carb, and/or calorie) counts for meals, you might be interested in Carb Pilot.)
Try different tasks and projects
You don’t have to start with complex projects. In fact, it’s better if you don’t. Start with tasks you already know how to do, but maybe want to see how the AI does. This could be summarizing text, writing or rewriting an email, changing formats of information (eg json to csv, or raw text into a table formatted so you can easily copy/paste it elsewhere).
Then branch out. Try something new you don’t know how to do, or tackle a challenge you’ve been avoiding.
There are two good categories of tasks you can try with AI:
- Tasks you already do, but want to do more efficiently
- Tasks you want to do, but aren’t sure how to begin
AI is a Skill, and Skills Take Practice
Using AI well is a skill. And like any skill, it improves with practice. It’s probably like managing an intern or a new coworker who’s new to your organization or field. The first time you managed someone, it probably wasn’t as good as after you had 5 years of practice managing people or helping interns get up to speed quickly. Over time, you figure out how to right-size tasks; repeat instructions or give them differently to meet people’s learning or communication styles; and circle back when needed when it’s clear your instructions may have been misunderstood or they’re heading off in a slightly unexpected direction.
Don’t let one bad experience with AI close the door. The people who are getting the most out of AI right now are the ones who keep trying. We experimented, failed, re-tried, and learned. That can be you, too.
If AI didn’t wow you the first time for the first task you tried, don’t quit. Rephrase your prompt. Try another model/tool. (Some people like ChatGPT; some people like Claude; some people like Gemini….etc.) You can also ask for help. (You can ask the LLM itself for help! Or ask a friendly human, I’m a friendly human you can try asking, for example, if you’re reading this post. DM or email me and tell me what you’re stuck on. If I can make suggestions, I will!)
Come back in a week. Try a new type of task. Try the same task again, with a fresh prompt.
But most importantly: keep trying. The more you do, the better it gets.
 TL;DR: as more and more people are going to vibe code their way to having Android and/or iOS apps, it’s very feasible for people with less experience to do both and to distribute apps on both platforms (iOS App Store and Google Play Store for Android). However, there’s an up front higher cost to iOS ($99/year) but a slightly easier, more intuitive experience for deploying your apps and getting them reviewed and approved. Conversely, Android development, despite its lower entry cost ($25 once), involves navigating a more complicated development environment, less intuitive deployment processes, and opaque requirements for app approval. You pay with your time, but if you plan to eventually build multiple apps, once you figure it out you can repeat the process more easily. Both are viable paths for app distribution if you’re building iOS and Android apps in the LLM-era of assisted coding, but don’t be surprised if you hit bumps in the road for deploying for testing or production.
TL;DR: as more and more people are going to vibe code their way to having Android and/or iOS apps, it’s very feasible for people with less experience to do both and to distribute apps on both platforms (iOS App Store and Google Play Store for Android). However, there’s an up front higher cost to iOS ($99/year) but a slightly easier, more intuitive experience for deploying your apps and getting them reviewed and approved. Conversely, Android development, despite its lower entry cost ($25 once), involves navigating a more complicated development environment, less intuitive deployment processes, and opaque requirements for app approval. You pay with your time, but if you plan to eventually build multiple apps, once you figure it out you can repeat the process more easily. Both are viable paths for app distribution if you’re building iOS and Android apps in the LLM-era of assisted coding, but don’t be surprised if you hit bumps in the road for deploying for testing or production. As things change in my body (I have several autoimmune diseases and have gained more over the years), my ‘budget’ on any given day has changed, and so have my priorities. During times when I feel like I’m struggling to get everything done that I want to prioritize, it sometimes feels like I don’t have enough energy to do it all, compared to other times when I’ve had sufficient energy to do the same amount of daily activities, and with extra energy left over. (
As things change in my body (I have several autoimmune diseases and have gained more over the years), my ‘budget’ on any given day has changed, and so have my priorities. During times when I feel like I’m struggling to get everything done that I want to prioritize, it sometimes feels like I don’t have enough energy to do it all, compared to other times when I’ve had sufficient energy to do the same amount of daily activities, and with extra energy left over. (

 It’s important to remember that even if the total amount of time is “a lot”, it doesn’t have to be done all at once. Historically, a lot of us might work 8 hour days (or longer days). For those of us with desk jobs, we sometimes have options to split this up. For example, working a few hours and then taking a lunch break, or going for a walk / hitting the gym, then returning to work. Instead of a static 9-5, it may look like 8-11:30, 1:30-4:30, 8-9:30.
It’s important to remember that even if the total amount of time is “a lot”, it doesn’t have to be done all at once. Historically, a lot of us might work 8 hour days (or longer days). For those of us with desk jobs, we sometimes have options to split this up. For example, working a few hours and then taking a lunch break, or going for a walk / hitting the gym, then returning to work. Instead of a static 9-5, it may look like 8-11:30, 1:30-4:30, 8-9:30.

 And: patients should not be punished for asking questions in order to better understand or check their understanding.
And: patients should not be punished for asking questions in order to better understand or check their understanding.  I’ve learned from experience that waiting rarely creates better outcomes. It only delays impact.
I’ve learned from experience that waiting rarely creates better outcomes. It only delays impact. (Thank you).
(Thank you). I encourage you to think about scaling yourself and identifying a task or series of tasks where you can get in the habit of leveraging these tools to do so. Like most things, the first time or two might take a little more time. But once you figure out what tasks or projects are suited for this, the time savings escalate. Just like learning how to use any new software, tool, or approach. A little bit of invested time up front will likely save you a lot of time in the future.
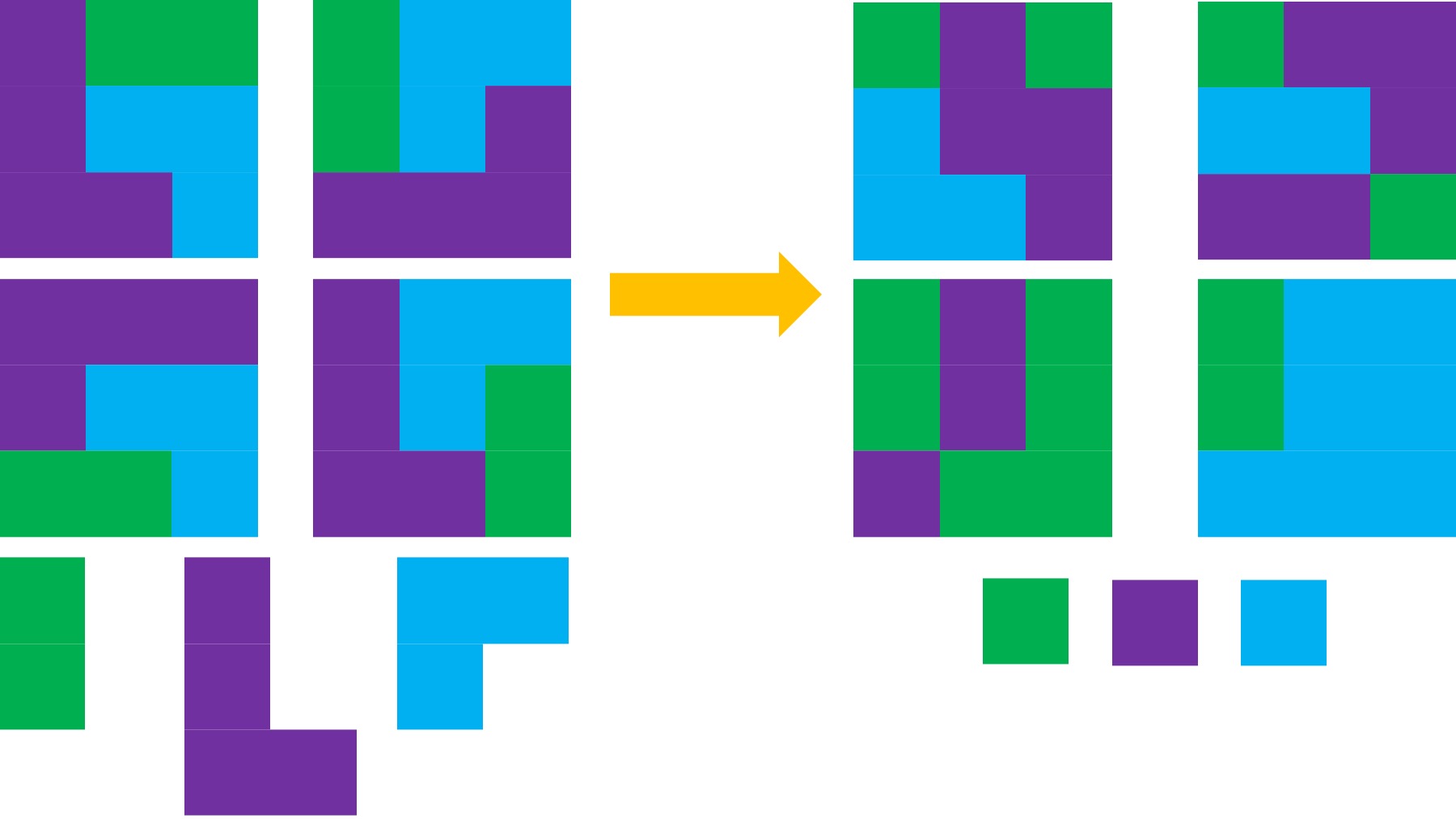
I encourage you to think about scaling yourself and identifying a task or series of tasks where you can get in the habit of leveraging these tools to do so. Like most things, the first time or two might take a little more time. But once you figure out what tasks or projects are suited for this, the time savings escalate. Just like learning how to use any new software, tool, or approach. A little bit of invested time up front will likely save you a lot of time in the future. If you have been prescribed pancreatic enzyme replacement therapy (PERT), aka enzymes for exocrine pancreatic insufficiency (EPI or PEI), you may be wondering how long it will take before you start to feel better or it starts to work. This is a common question, and the answer depends on several factors, including the dosage, meal composition, and how well your body uses the enzymes. Some improvements can be seen within a single meal, while other benefits take longer to manifest. It also depends on whether you have EPI, or if you have EPI in concert with other types of gastrointestinal conditions, because some of your symptoms may be coming from other conditions.
If you have been prescribed pancreatic enzyme replacement therapy (PERT), aka enzymes for exocrine pancreatic insufficiency (EPI or PEI), you may be wondering how long it will take before you start to feel better or it starts to work. This is a common question, and the answer depends on several factors, including the dosage, meal composition, and how well your body uses the enzymes. Some improvements can be seen within a single meal, while other benefits take longer to manifest. It also depends on whether you have EPI, or if you have EPI in concert with other types of gastrointestinal conditions, because some of your symptoms may be coming from other conditions.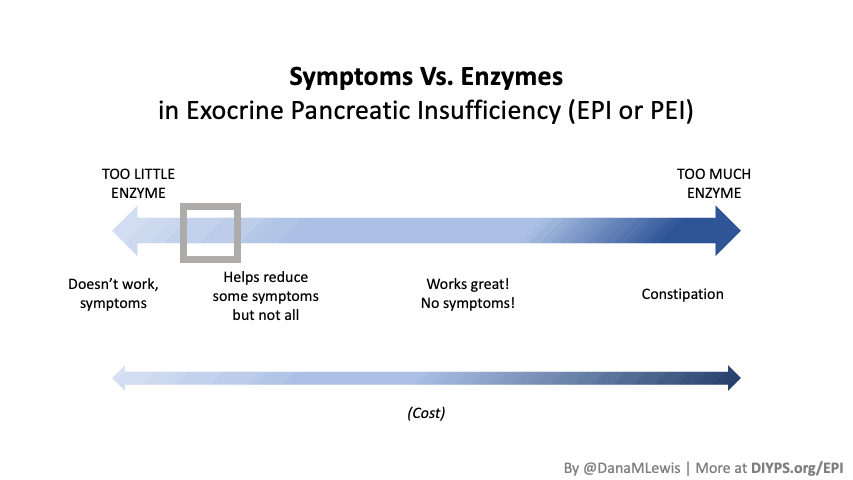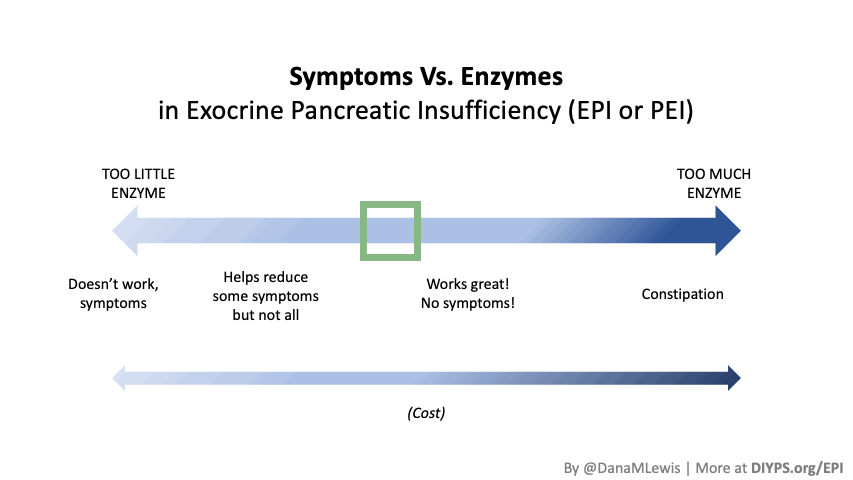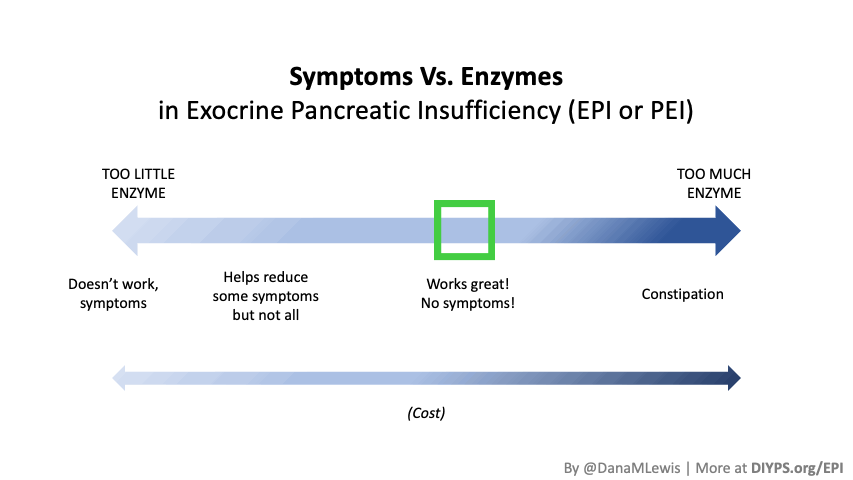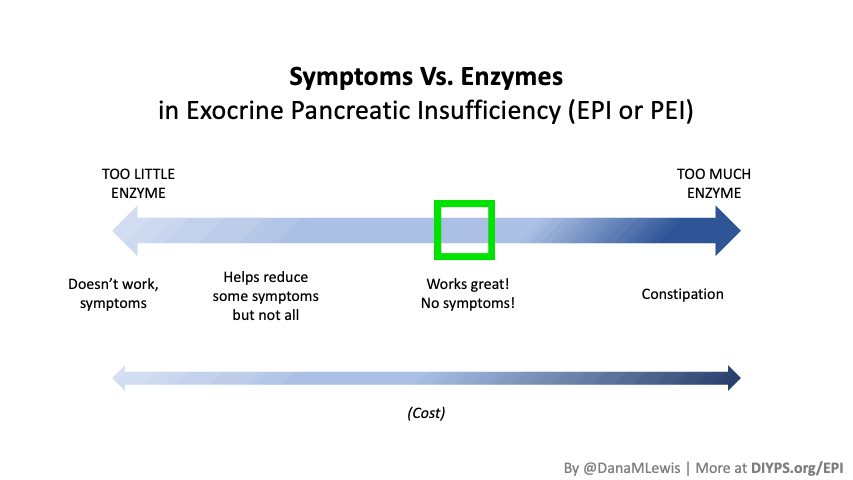
 TL;DR: Instead of arbitrarily lowering or increasing fat or fiber in the diet, measure and estimate what you are consuming first. If you have EPI,
TL;DR: Instead of arbitrarily lowering or increasing fat or fiber in the diet, measure and estimate what you are consuming first. If you have EPI,  It occurred to me that maybe I could tweak it somehow and make the bullets of the list represent food items. I wasn’t sure how, so I asked the LLM if it was possible. Because I’ve done my other ‘design’ work in PowerPoint, I went there and quickly dropped some shapes and lines to simulate the icon, then tested exporting – yes, you can export as SVG! I spent a few more minutes tweaking versions of it and exporting it. It turns out, yes, you can export as SVG, but then the way I designed it wasn’t really suited for SVG use. When I had dropped the SVG into XCode, it didn’t show up. I asked the LLM again and it suggested trying PNG format. I exported the icon from powerpoint as PNG, dropped it into XCode, and it worked!
It occurred to me that maybe I could tweak it somehow and make the bullets of the list represent food items. I wasn’t sure how, so I asked the LLM if it was possible. Because I’ve done my other ‘design’ work in PowerPoint, I went there and quickly dropped some shapes and lines to simulate the icon, then tested exporting – yes, you can export as SVG! I spent a few more minutes tweaking versions of it and exporting it. It turns out, yes, you can export as SVG, but then the way I designed it wasn’t really suited for SVG use. When I had dropped the SVG into XCode, it didn’t show up. I asked the LLM again and it suggested trying PNG format. I exported the icon from powerpoint as PNG, dropped it into XCode, and it worked!
Recent Comments