Some of the popular use cases of AI agents are to build custom software for other people, and sell it cheaper than big corporate software but still giving you a really good return on your time. A lot of people are quickly making good chunks of money doing that, and automating their workflows so they can make money while they sleep, so to speak. It’s often referred to as passive income, whether that’s investments or a product or business that can generate income for you without you having to do everything.
Some of us, though, are taking a different approach. Not a new one, though, although AI is helping us scale our efforts. This type of approach has been common through open source software for decades. The idea is that you can build something that will help other people…including yes, while you sleep. Instead of passive income, it’s passive impact.
We can think about using our time, skills, and output of our work not for financial profit, but for people’s benefit, by reaching more people and being useful to people we don’t even know. The goal isn’t making money, it’s to help more people.
Some people do pursue financial income to make an impact. I’m not saying not to do that, if that’s your path of choice. You can maximize your income, then donate to causes you care about. It’s a great strategy for a lot of people who have lucrative careers, and there are a lot of causes (like Life For a Child, which we estimate is the most cost-effective way to help people with diabetes worldwide) that can scale their work with your help through financial donations.
Other people maybe don’t have the same income earning potential or have chosen less financially lucrative careers where their work makes a difference, or they volunteer their time and elbow grease outside of their work to make a difference.
Both of those are great. Yet, I’m saying “yes and” there’s a third option we should talk about more in general society: scaling impact asynchronously and building things for passive impact.
These are things that don’t just solve a one-time problem for one person. They can solve a one-time problem for a lot of people, or a recurring problem for other people.
They scale.
They persist.
What are some examples of passive impact? Think about things that can run without you.
- A blog post or other types of writing explaining something that helps other people who might be in the same situation.
- Some of my blog posts that I think about in this category include:
- Dealing with a broken ankle and returning to weight bearing that still gets hundreds of visits a month from people who have newly arrived in the situation
- Explaining out how to match the amount of pancreatic enzyme replacement therapy (PERT) to what you are eating and learning to adjust enzyme dosing and food intake, so other people with exocrine pancreatic insufficiency (EPI / PEI) can use this method.
- Describing how to do “eating soon” mode to get a little insulin activity going in the body, without risking hypoglycemia, for people with type 1 diabetes
- What else fits into this category? Documentation. This could be step by step documentation of how to do/automate something (like the OpenAPS documentation that walks people through building their own open-source automated insulin delivery system) or high level documentation, like the plain language OpenAPS reference design that has been the beacon of understanding for developers, users, and researchers for the last decade.
- Some of my blog posts that I think about in this category include:
- A structured method for doing something that maybe you did by hand or in a custom format, but other people would benefit from having in a structured way.
- Some of the things I’ve built for this include:
- A symptom survey for people with exocrine pancreatic insufficiency to quantify symptoms based on frequency and severity, since there previously was no accessible way to score EPI-related symptoms.
- Carb Pilot, an iOS app that allows people to put in plain language meal descriptions and combines with the system prompt I wrote to generate macronutrient estimates.
- PERT Pilot, available both in iOS and Android, which allows people to do the above meal estimation feature but also, crucially, record and visualize their meal outcomes based on their enzyme dosing. Previously, there were zero enzyme trackers for people with EPI.
- Some of the things I’ve built for this include:
They don’t require a calendar invite or a Zoom link. They don’t need a customer service rep. They just… work. For someone. Somewhere. Every day.
Note that these tools don’t have to work for EVERYONE. Most of my stuff is considered “niche”. I was asked countless times early on why I thought OpenAPS would work for everyone with diabetes. People were surprised when I said I didn’t think it would work for everyone, but it would probably work for everyone who wanted it. (Then we did a lot of research and proved that). Not everyone needed or wanted it, but that doesn’t mean that it wasn’t worthwhile to build for me, or me plus the first dozen, or me plus the now tens of thousands of people using the OpenAPS algorithm in their AID system. But that’s “just” a “small fraction” of “only people with type 1 diabetes” who are “a tiny part of the population of the world”. It doesn’t matter; those people still matter and they (and I!) benefitted from that work, so it was worth doing. The impact scaled.
(You don’t have to quantify it all, but some metrics are helpful)
As someone who builds a lot of things with passive impact, it’s helpful to have data or some kind of analytics to see use of what I built over time. It’s useful for identifying where there are areas to improve, such as if people are stuck when using a feature or finding a bug, but also reinforcing the scale of your impact.
I love waking up and seeing the volume of meal data that’s been processed through Carb Pilot or PERT Pilot (measured via API use metrics), to know that while I was sleeping on the west coast of the US, several people woke up in (likely Europe or elsewhere) and used one of my apps to estimate what they had for breakfast. It’s great reinforcement and you can also see whether you’re gaining exponential growth (in terms of overall usage or new users) over time, and perhaps consider whether you should do a little more sharing about what you’ve built so it can reach the right people before it takes off on its own. Again, not for profit, but for helping.
(But passive impact doesn’t mean passive effort)
Creating something helpful is not passive in the beginning. It takes work, and elbow grease, to understand the problem you are (or someone else is) facing. To be able to determine a useful solution. To build, or write, something that other people can use, without needing to explain it every time. To deploy or share or host it in a way that is accessible and usable long-term. Of course, there are increasing numbers of tools (like LLMs – here are some of my tips for getting started if you’re new to prompting) that can help you get started more quickly, or find a fix to a bug or project blocker, or try something new you didn’t know how to do before.
But once it’s live, the math changes. One hour of your time can help hundreds of people, without requiring hundreds of hours. A lot of times it may be more than one hour, but nowadays, it’s often a lot less than it would have been otherwise. And more likely, you may find yourself spending multiple hours building something and be frustrated (well, I often get frustrated) at “how long it’s taking”, then realize that if you don’t build it, no one will. And without this effort, it wouldn’t get built at all. So it’s worth the >one hour time it’s taking to build it, even if it’s longer than expected.
That’s how a lot of my projects started: I needed something, I built it, and then I realized others needed it too. So I built (or wrote) it and shared it.
That’s passive impact, and it adds up.

I’d love to see more of this in the world. And I’d love to see an understanding that this IS the goal, not financial outcomes, and that’s a valid and celebratable goal. (This comment is motivated by having someone ask me in recent weeks asking how much royalties I’m getting from the open source code we released 10 years ago, intentionally free, with the goal of companies using it!) But preferably not followed with “I could never do that”, because, of course, you could. You can. You…should? Maybe, maybe not. But hopefully you think about it in the future. It’s not “either or” with financial income, either. You can do both! Society spends a lot of time talking about how to earn money passively. But not nearly enough time thinking about how we can create value for others passively. Especially in health, technology, and research spaces (fields where gaps are common and timely help matters), this way of thinking can change not just how we build, but who we build for. We can bring more people into using or building or doing, whether it’s active or passive. And we all win as a result.
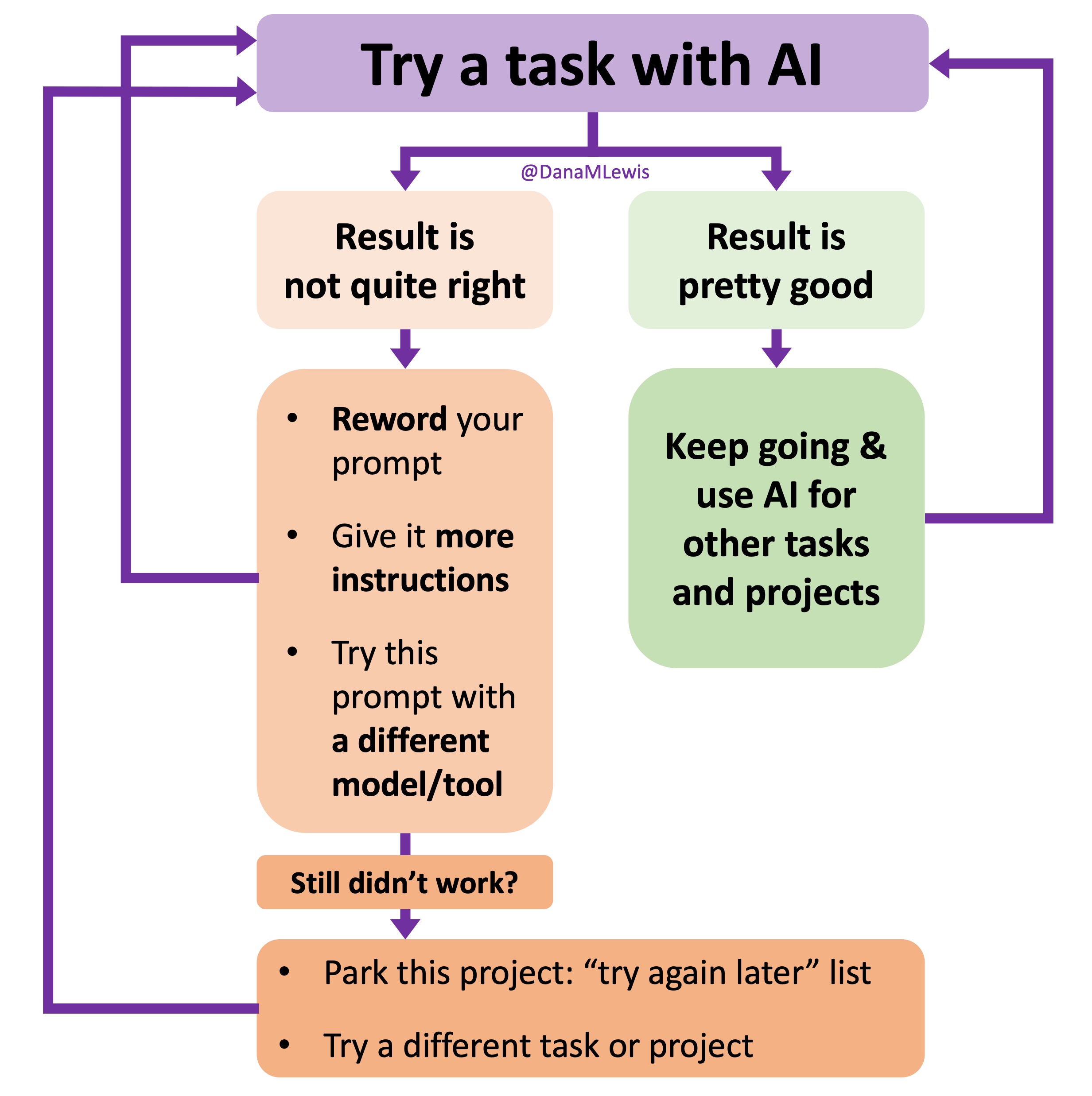 I’ve started making a list of projects or tasks I want to work on where the AI isn’t quite there yet and/or I haven’t figured out a good setup, the right tool, etc. A good example of this was
I’ve started making a list of projects or tasks I want to work on where the AI isn’t quite there yet and/or I haven’t figured out a good setup, the right tool, etc. A good example of this was  TL;DR: as more and more people are going to vibe code their way to having Android and/or iOS apps, it’s very feasible for people with less experience to do both and to distribute apps on both platforms (iOS App Store and Google Play Store for Android). However, there’s an up front higher cost to iOS ($99/year) but a slightly easier, more intuitive experience for deploying your apps and getting them reviewed and approved. Conversely, Android development, despite its lower entry cost ($25 once), involves navigating a more complicated development environment, less intuitive deployment processes, and opaque requirements for app approval. You pay with your time, but if you plan to eventually build multiple apps, once you figure it out you can repeat the process more easily. Both are viable paths for app distribution if you’re building iOS and Android apps in the LLM-era of assisted coding, but don’t be surprised if you hit bumps in the road for deploying for testing or production.
TL;DR: as more and more people are going to vibe code their way to having Android and/or iOS apps, it’s very feasible for people with less experience to do both and to distribute apps on both platforms (iOS App Store and Google Play Store for Android). However, there’s an up front higher cost to iOS ($99/year) but a slightly easier, more intuitive experience for deploying your apps and getting them reviewed and approved. Conversely, Android development, despite its lower entry cost ($25 once), involves navigating a more complicated development environment, less intuitive deployment processes, and opaque requirements for app approval. You pay with your time, but if you plan to eventually build multiple apps, once you figure it out you can repeat the process more easily. Both are viable paths for app distribution if you’re building iOS and Android apps in the LLM-era of assisted coding, but don’t be surprised if you hit bumps in the road for deploying for testing or production. As things change in my body (I have several autoimmune diseases and have gained more over the years), my ‘budget’ on any given day has changed, and so have my priorities. During times when I feel like I’m struggling to get everything done that I want to prioritize, it sometimes feels like I don’t have enough energy to do it all, compared to other times when I’ve had sufficient energy to do the same amount of daily activities, and with extra energy left over. (
As things change in my body (I have several autoimmune diseases and have gained more over the years), my ‘budget’ on any given day has changed, and so have my priorities. During times when I feel like I’m struggling to get everything done that I want to prioritize, it sometimes feels like I don’t have enough energy to do it all, compared to other times when I’ve had sufficient energy to do the same amount of daily activities, and with extra energy left over. (

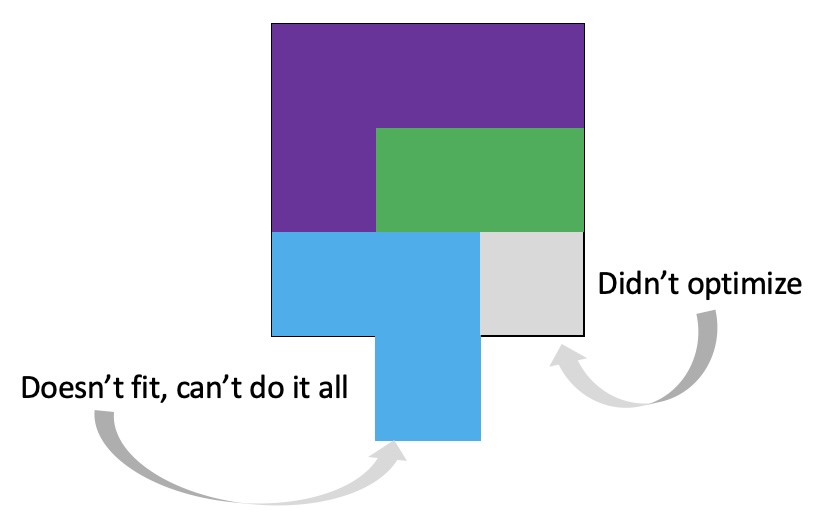 It’s important to remember that even if the total amount of time is “a lot”, it doesn’t have to be done all at once. Historically, a lot of us might work 8 hour days (or longer days). For those of us with desk jobs, we sometimes have options to split this up. For example, working a few hours and then taking a lunch break, or going for a walk / hitting the gym, then returning to work. Instead of a static 9-5, it may look like 8-11:30, 1:30-4:30, 8-9:30.
It’s important to remember that even if the total amount of time is “a lot”, it doesn’t have to be done all at once. Historically, a lot of us might work 8 hour days (or longer days). For those of us with desk jobs, we sometimes have options to split this up. For example, working a few hours and then taking a lunch break, or going for a walk / hitting the gym, then returning to work. Instead of a static 9-5, it may look like 8-11:30, 1:30-4:30, 8-9:30.

 I’ve learned from experience that waiting rarely creates better outcomes. It only delays impact.
I’ve learned from experience that waiting rarely creates better outcomes. It only delays impact. I encourage you to think about scaling yourself and identifying a task or series of tasks where you can get in the habit of leveraging these tools to do so. Like most things, the first time or two might take a little more time. But once you figure out what tasks or projects are suited for this, the time savings escalate. Just like learning how to use any new software, tool, or approach. A little bit of invested time up front will likely save you a lot of time in the future.
I encourage you to think about scaling yourself and identifying a task or series of tasks where you can get in the habit of leveraging these tools to do so. Like most things, the first time or two might take a little more time. But once you figure out what tasks or projects are suited for this, the time savings escalate. Just like learning how to use any new software, tool, or approach. A little bit of invested time up front will likely save you a lot of time in the future. TL;DR: Instead of arbitrarily lowering or increasing fat or fiber in the diet, measure and estimate what you are consuming first. If you have EPI,
TL;DR: Instead of arbitrarily lowering or increasing fat or fiber in the diet, measure and estimate what you are consuming first. If you have EPI,  It occurred to me that maybe I could tweak it somehow and make the bullets of the list represent food items. I wasn’t sure how, so I asked the LLM if it was possible. Because I’ve done my other ‘design’ work in PowerPoint, I went there and quickly dropped some shapes and lines to simulate the icon, then tested exporting – yes, you can export as SVG! I spent a few more minutes tweaking versions of it and exporting it. It turns out, yes, you can export as SVG, but then the way I designed it wasn’t really suited for SVG use. When I had dropped the SVG into XCode, it didn’t show up. I asked the LLM again and it suggested trying PNG format. I exported the icon from powerpoint as PNG, dropped it into XCode, and it worked!
It occurred to me that maybe I could tweak it somehow and make the bullets of the list represent food items. I wasn’t sure how, so I asked the LLM if it was possible. Because I’ve done my other ‘design’ work in PowerPoint, I went there and quickly dropped some shapes and lines to simulate the icon, then tested exporting – yes, you can export as SVG! I spent a few more minutes tweaking versions of it and exporting it. It turns out, yes, you can export as SVG, but then the way I designed it wasn’t really suited for SVG use. When I had dropped the SVG into XCode, it didn’t show up. I asked the LLM again and it suggested trying PNG format. I exported the icon from powerpoint as PNG, dropped it into XCode, and it worked! If you can shift your mindset from fear and avoidance to curiosity and experimentation, you might discover new skills, solve problems you once thought were impossible, and open up entirely new opportunities.
If you can shift your mindset from fear and avoidance to curiosity and experimentation, you might discover new skills, solve problems you once thought were impossible, and open up entirely new opportunities. TLDR: Instead of asking “Which model is best?”, a better question might be:
TLDR: Instead of asking “Which model is best?”, a better question might be:
Recent Comments