Talking about AI (artificial intelligence) often veers conversations toward lofty, futuristic scenarios. But there’s a quieter, more fundamental way AI is making a big difference today: serving as an accessibility tool that helps many of us to accomplish tasks more efficiently and comfortably than otherwise would be possible. And often, enabling us to complete tasks we might otherwise avoid or be unable to do at all.
One way to think about AI is as the ultimate translator. But I don’t just mean between languages: I mean between ways of interacting with the world.
Imagine you’re someone dealing with a repetitive stress injury like carpal tunnel syndrome, making prolonged typing painful or even impossible. Traditionally, you might use dictation software to turn spoken words into text, alleviating physical strain. No issues with that, right? But somehow, suggesting people use AI tools to do the same thing (dictation and cleaning up of the dictated text) causes skepticism about “cheating” the “correct” way of doing things. If you imagine the carpal tunnel scenario, that’s less likely to be a reaction, but imagine many other situations where you see outrage and disgust (as a knee jerk reaction) to the idea of people using AI.
In reality, there are three ways of doing things to accomplish a note-taking task:
- A human types notes
- A human speaks notes to a voice dictation tool
- A human speaks notes to an AI-based dictation tool, that also when prompted could clean up and transform the notes into different formats.
All three introduce the possibility of errors. The difference is how we perceive and tolerate those errors: the perception often reflects bias rather than logic.
For example, the focus disproportionately in the third example is about errors, where errors might not even come up in the other two. OMG, the AI might do something wrong! It might hallucinate an error! Well, yes, it might. But so too does the dictation software. There was similar outrage years ago when voice dictation software became common for doctors to use to dictate their chart notes. And yes, there were and are errors there, too. And guess what? Humans typing notes? ALSO RESULTS IN ERRORS. The important thing here is all three cases: human alone, human plus basic tech, human plus AI, all result in the possibility of errors.
(I actually see this frequently, where I see three different providers who either use voice dictation to write my chart notes, introducing errors; AI-assisted notetaking, occasionally introducing errors; and one manually types all of their notes…still occasionally introducing errors. They’re typically different types of errors, but the result is the same: error!)
This is more about cultural change than it is about the errors in and of themselves. If people actually cared about the errors, we would be creating pathways to fix errors by humans and other approaches, such as enabling wiki-style editing requests of medical charts so that patients and providers can collaboratively update and keep medical records and chart notes free of errors so they don’t propagate over time. This almost never happens: chart notes can only be corrected by providers, and patients often have to use scarce visit time if they care enough to request a correction. Instead, most discussions focus more on where theoretical errors came from rather than practical approaches to fix real-world errors.
Back to AI specifically:
Note taking is a simplistic example of what can be useful with AI, but there’s more examples of transformation, such as transforming data into different formats. Converting data from JSON to CSV or vice versa – this is a task that can be tedious or impossible for some people. Sure, this could be done manually, or it can be done with hand-written scripts for transforming the data, or it can be done by having an AI write the scripts to transform that data, or it can be done with the AI writing and executing the scripts to “transform the data itself”. AI can often do all of these steps quickly and efficiently, triggered by a plain-language request (either typed or dictated by voice).
Here are other examples where AI can be an accessibility tool:
- A visually impaired user has AI describe images and generate ALT text and/or convert unreadable PDFs into something their screen reader can use. They might also have the AI summarize the text, first, to see if they want to bother spending the time screen reading all that text.
- Individuals with mobility limitations control their home environment or work environment, by using AI to pair together tools that allow them to do things that weren’t possible before, and can brainstorm solutions to problems that previously they didn’t know how to solve or didn’t have the tools to solve or build.
- People in a country where they don’t speak the language and are needing to access the healthcare system can benefit from real-time AI translation when there’s no medical interpreter services, if they bring their own AI translator. US healthcare providers are generally prohibited from using such tools and are forced to forego translation entirely when human translators are not available.
- People with disabilities (whether those are mental or physical) using AI to help understand important healthcare or insurance forms or paperwork they need to understand or interpret and take action on.
Personally, I keep finding endless ways where AI is an accessibility tool for me, in large and small ways. And the small ways often add up to a lot of time saved.
One frequent example where I keep using it is for finding and customizing hikes. Last year, I had to change my exercise strategy, which included hiking more instead of running. Increasingly since then, though, I also have had to modify which hikes I’m able to do, including factoring in the terrain. (Super rocky or loose rock terrain are challenging whereas they used to not be a limitation). I used to spend a lot of time researching hikes based on location, then round trip distance, then elevation gain, then read trail descriptions and trail reports from recent weeks and months to ensure that a hike would be a good candidate for me. This actually took quite a bit of time to do manually (for context, we did 61 hikes last year!).
But with AI, I can give an LLM the parameters of geography (eg hikes along the I-90 corridor or less than two hours from Seattle), round trip mileage and elevation limits, *and* ask it to search and exclude any hikes with long sections of loose, rocky or technical terrain. I can also say things like “find hikes similar to the terrain of Rattlesnake Ledge”, which is a smooth terrain hike. This cuts down and creates a short list that meets my criteria so I can spend my time picking between hikes that already meet all my criteria, and confirming the AI’s assessment with my own quick read of the trail description and trail reviews.
It’s a great use of AI to more quickly do burdensome tasks, and it’s actually found several great hikes that I wouldn’t have found by manual searching, which is expanding my ‘horizons’ even when it feels like I’m being limited by the increasing number of restrictions/criteria that I need to plan around. Which is awesome. As hiking itself gets harder, the effort it takes to find doable hikes with my new criteria is actually much less, which means the cost-effort ratio of finding and doing things continues to evolve so that hiking continues to be something I do rather than giving it up completely (and drastically reducing my physical activity levels).
Whenever I see knee jerk reactions along the lines of “AI is bad!” and “you shouldn’t use it that way!” it often comes from a place of projecting the way people “should” do things (in a perfect world). But the reality is, a lot of times people can’t do things the same way, because of a disability or otherwise.
 AI often gives us new capabilities to do these things, even if it’s different from the way someone might do it manually or without the disability. And for us, it’s often not a choice of “do it manually or do it differently” but a choice of “do, with AI, or don’t do at all because it’s not possible”. Accessibility can be about creating equitable opportunities, and it can also be about preserving energy, reducing pain, enhancing dignity, and improving quality of life in the face of living with a disability (or multiple disabilities). AI can amplify our existing capabilities and super powers, but it can also level the playing field and allow us to do more than we could before, more easily, with fewer barriers.
AI often gives us new capabilities to do these things, even if it’s different from the way someone might do it manually or without the disability. And for us, it’s often not a choice of “do it manually or do it differently” but a choice of “do, with AI, or don’t do at all because it’s not possible”. Accessibility can be about creating equitable opportunities, and it can also be about preserving energy, reducing pain, enhancing dignity, and improving quality of life in the face of living with a disability (or multiple disabilities). AI can amplify our existing capabilities and super powers, but it can also level the playing field and allow us to do more than we could before, more easily, with fewer barriers.
Remember, AI helps us do more – and it also helps more of us do things at all.
 These are actionable, doable, practical things we can all be doing, today, and not just gnashing our teeth. The sooner we course correct with improved data availability, the better off we’ll all be in the future, whether that’s tomorrow with better clinical care or in years with AI-facilitated diagnoses, treatments, and cures.
These are actionable, doable, practical things we can all be doing, today, and not just gnashing our teeth. The sooner we course correct with improved data availability, the better off we’ll all be in the future, whether that’s tomorrow with better clinical care or in years with AI-facilitated diagnoses, treatments, and cures. 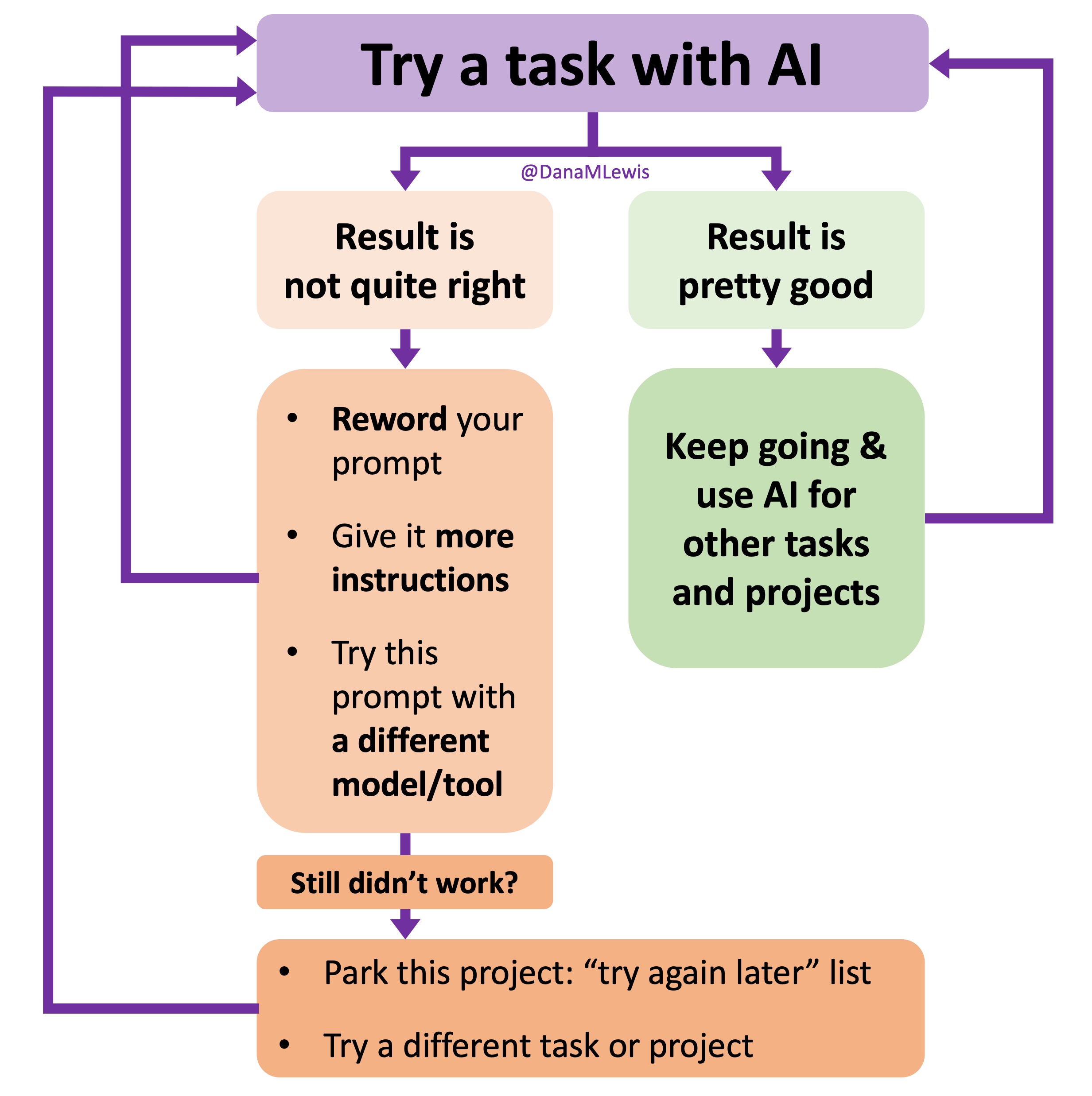 I’ve started making a list of projects or tasks I want to work on where the AI isn’t quite there yet and/or I haven’t figured out a good setup, the right tool, etc. A good example of this was
I’ve started making a list of projects or tasks I want to work on where the AI isn’t quite there yet and/or I haven’t figured out a good setup, the right tool, etc. A good example of this was  TL;DR: as more and more people are going to vibe code their way to having Android and/or iOS apps, it’s very feasible for people with less experience to do both and to distribute apps on both platforms (iOS App Store and Google Play Store for Android). However, there’s an up front higher cost to iOS ($99/year) but a slightly easier, more intuitive experience for deploying your apps and getting them reviewed and approved. Conversely, Android development, despite its lower entry cost ($25 once), involves navigating a more complicated development environment, less intuitive deployment processes, and opaque requirements for app approval. You pay with your time, but if you plan to eventually build multiple apps, once you figure it out you can repeat the process more easily. Both are viable paths for app distribution if you’re building iOS and Android apps in the LLM-era of assisted coding, but don’t be surprised if you hit bumps in the road for deploying for testing or production.
TL;DR: as more and more people are going to vibe code their way to having Android and/or iOS apps, it’s very feasible for people with less experience to do both and to distribute apps on both platforms (iOS App Store and Google Play Store for Android). However, there’s an up front higher cost to iOS ($99/year) but a slightly easier, more intuitive experience for deploying your apps and getting them reviewed and approved. Conversely, Android development, despite its lower entry cost ($25 once), involves navigating a more complicated development environment, less intuitive deployment processes, and opaque requirements for app approval. You pay with your time, but if you plan to eventually build multiple apps, once you figure it out you can repeat the process more easily. Both are viable paths for app distribution if you’re building iOS and Android apps in the LLM-era of assisted coding, but don’t be surprised if you hit bumps in the road for deploying for testing or production. As things change in my body (I have several autoimmune diseases and have gained more over the years), my ‘budget’ on any given day has changed, and so have my priorities. During times when I feel like I’m struggling to get everything done that I want to prioritize, it sometimes feels like I don’t have enough energy to do it all, compared to other times when I’ve had sufficient energy to do the same amount of daily activities, and with extra energy left over. (
As things change in my body (I have several autoimmune diseases and have gained more over the years), my ‘budget’ on any given day has changed, and so have my priorities. During times when I feel like I’m struggling to get everything done that I want to prioritize, it sometimes feels like I don’t have enough energy to do it all, compared to other times when I’ve had sufficient energy to do the same amount of daily activities, and with extra energy left over. (

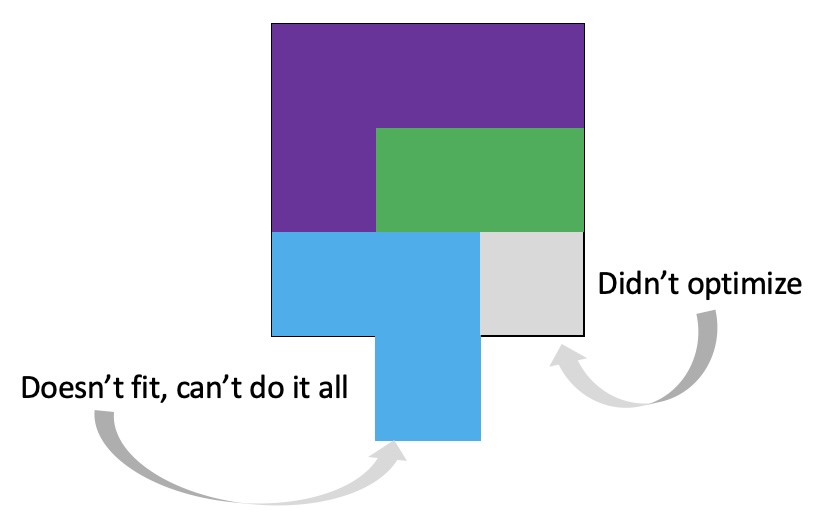 It’s important to remember that even if the total amount of time is “a lot”, it doesn’t have to be done all at once. Historically, a lot of us might work 8 hour days (or longer days). For those of us with desk jobs, we sometimes have options to split this up. For example, working a few hours and then taking a lunch break, or going for a walk / hitting the gym, then returning to work. Instead of a static 9-5, it may look like 8-11:30, 1:30-4:30, 8-9:30.
It’s important to remember that even if the total amount of time is “a lot”, it doesn’t have to be done all at once. Historically, a lot of us might work 8 hour days (or longer days). For those of us with desk jobs, we sometimes have options to split this up. For example, working a few hours and then taking a lunch break, or going for a walk / hitting the gym, then returning to work. Instead of a static 9-5, it may look like 8-11:30, 1:30-4:30, 8-9:30.

 I encourage you to think about scaling yourself and identifying a task or series of tasks where you can get in the habit of leveraging these tools to do so. Like most things, the first time or two might take a little more time. But once you figure out what tasks or projects are suited for this, the time savings escalate. Just like learning how to use any new software, tool, or approach. A little bit of invested time up front will likely save you a lot of time in the future.
I encourage you to think about scaling yourself and identifying a task or series of tasks where you can get in the habit of leveraging these tools to do so. Like most things, the first time or two might take a little more time. But once you figure out what tasks or projects are suited for this, the time savings escalate. Just like learning how to use any new software, tool, or approach. A little bit of invested time up front will likely save you a lot of time in the future. It occurred to me that maybe I could tweak it somehow and make the bullets of the list represent food items. I wasn’t sure how, so I asked the LLM if it was possible. Because I’ve done my other ‘design’ work in PowerPoint, I went there and quickly dropped some shapes and lines to simulate the icon, then tested exporting – yes, you can export as SVG! I spent a few more minutes tweaking versions of it and exporting it. It turns out, yes, you can export as SVG, but then the way I designed it wasn’t really suited for SVG use. When I had dropped the SVG into XCode, it didn’t show up. I asked the LLM again and it suggested trying PNG format. I exported the icon from powerpoint as PNG, dropped it into XCode, and it worked!
It occurred to me that maybe I could tweak it somehow and make the bullets of the list represent food items. I wasn’t sure how, so I asked the LLM if it was possible. Because I’ve done my other ‘design’ work in PowerPoint, I went there and quickly dropped some shapes and lines to simulate the icon, then tested exporting – yes, you can export as SVG! I spent a few more minutes tweaking versions of it and exporting it. It turns out, yes, you can export as SVG, but then the way I designed it wasn’t really suited for SVG use. When I had dropped the SVG into XCode, it didn’t show up. I asked the LLM again and it suggested trying PNG format. I exported the icon from powerpoint as PNG, dropped it into XCode, and it worked! TLDR: Instead of asking “Which model is best?”, a better question might be:
TLDR: Instead of asking “Which model is best?”, a better question might be:
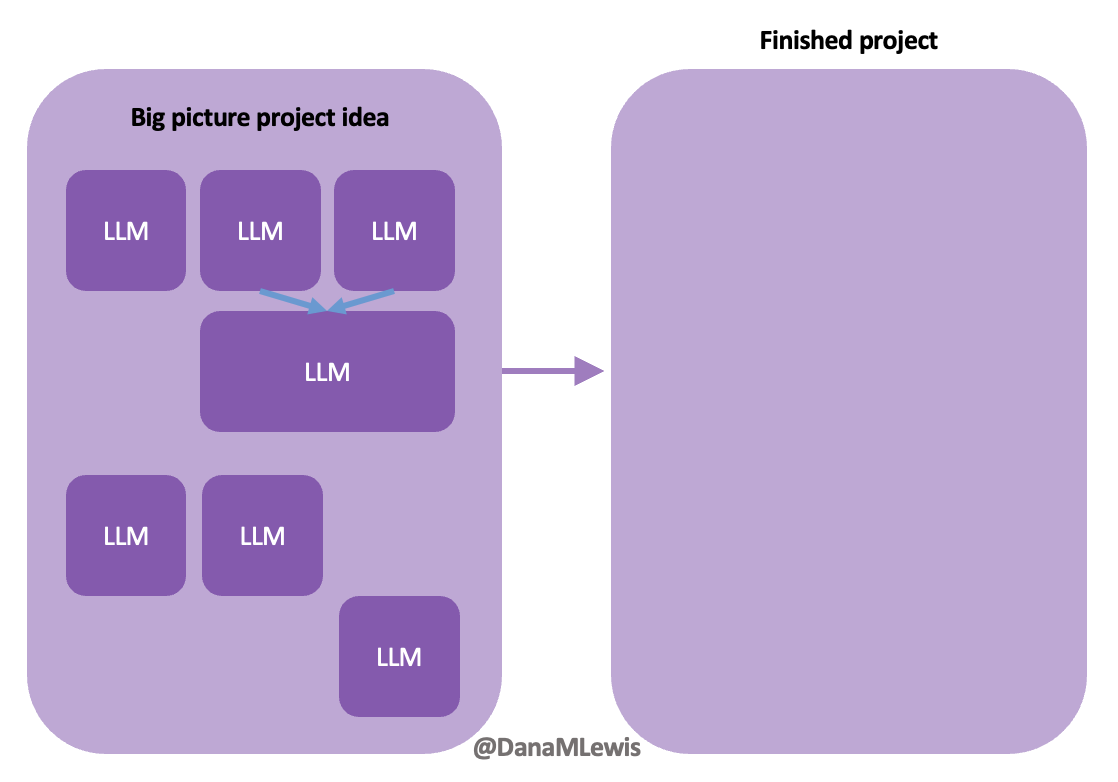 Today, I would say the same is true. It doesn’t matter – for my types of projects – if a human or an LLM “wrote” the code. What matters is: does it work as intended? Does it achieve the goal? Does it contribute to the goal of the project?
Today, I would say the same is true. It doesn’t matter – for my types of projects – if a human or an LLM “wrote” the code. What matters is: does it work as intended? Does it achieve the goal? Does it contribute to the goal of the project?
Recent Comments